- Published on
蒙特卡洛树搜索 Monte Carlo Tree Search
- Authors

- Name
- ZHOU Bin
- @bzhouxyz
我们前面提到的动态规划,其实已经有搜索的影子了,我们以八皇后问题为例:
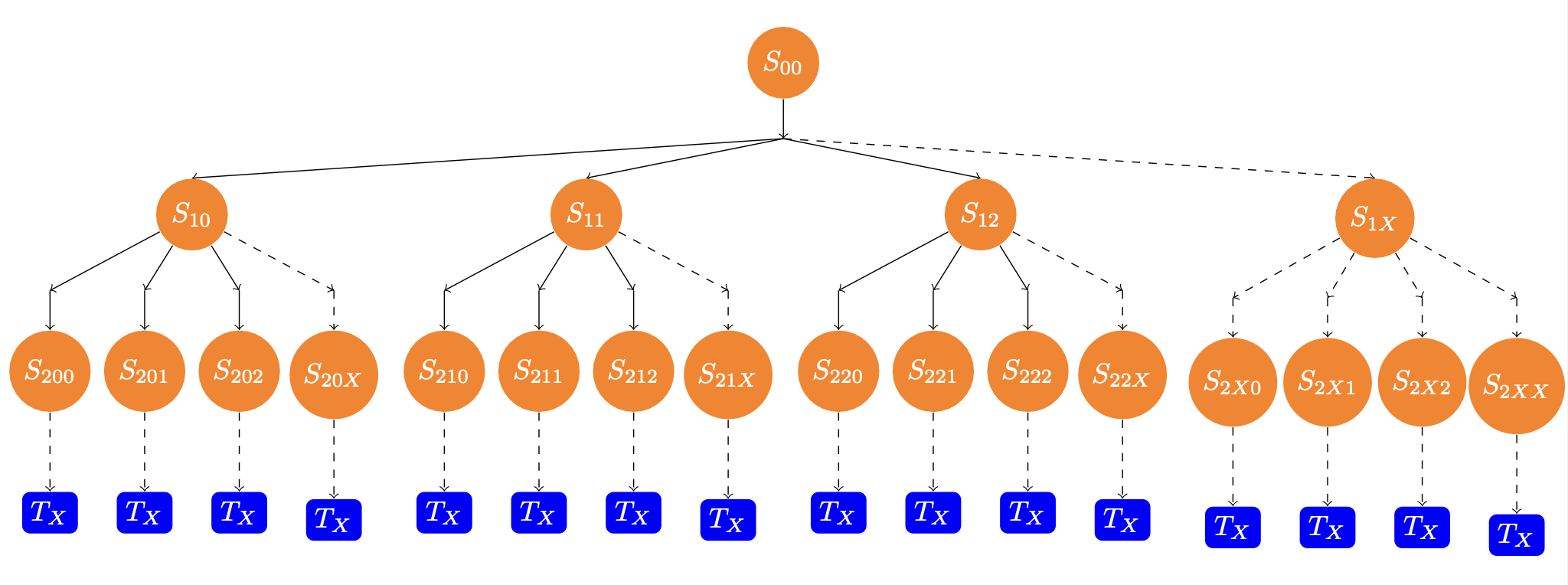
初始状态的空棋盘为, 我们每按规则放下一个皇后,就产生一个分支子节点,对应一个新的棋盘,直到无法再放置皇后或者棋盘满8个皇后为止,这就对应着一个终止节点。穷尽所有可能,就产生了类似于上图的树形图。
对八皇后问题,这个树的最大深度为,每个节点最多可产生的子节点为,由此可简单的估算这个问题的复杂度约为
对于现代计算机来说,这并不是个很大的数字,所以完全可以用穷举法找出所有解法。然而,一旦问题的深度和广度增加,这种简单的穷举在现有的硬件条件下就行不通了,比如说围棋,棋盘大小为,一盘棋一般下 个会和,简单估算其复杂度为
John Tromp 算出了19路棋盘的所有合法状态数的精确值,约为,比我们的估算要小的多。即便如此,在看得到的未来,也没有计算机能储存下这么多状态。
显然,我们需要更聪明的算法来解决更复杂的问题,即便找不到最优解,也能退而求其次的找到较优解。那么本文的主角蒙特卡洛树搜索就此登场。
Introduction
蒙特卡洛树搜索(MCTS)是众多棋牌类游戏AI的核心框架,早在上个世纪,该算法的变种就已经在超级计算机深蓝上战胜了当时的国际象棋世界冠军卡斯巴罗夫,轰动一时。但是由于围棋过高的复杂度,在深度学习被应用在该算法上之前,魔改后的MCTS在围棋上也只能勉强战胜人类的业余选手。直到2015年底,谷歌旗下的DeepMind公司将强化学习,深度学习和MCTS融为一体,借助强劲的算力,这个被命名为AlphaGo的AI程序,战胜了当时的欧洲围棋冠军樊辉,并在2016年战胜了当时的世界冠军,韩国职业九段棋手李世石,拉开了新一轮AI科技浪潮的序幕。
回到之前的问题,要想搜索程序运行的复杂度,很自然的会从两方面入手,即减少树搜索的深度和广度。在棋牌类游戏中,一方面我们不必穷尽所有路数,在某个游戏节点,我们只需要着重考虑个别看起来更合理的路数,这即是减少搜索的广度;另一方面,我们不用将某个游戏节点穷尽到底,只需大概评估该节点的局势谁更占优即可,这即是减少搜索的深度。
以上就是算法的核心思路。有关MCTS的详解,推荐阅读附件中的Survey。
Algorithm
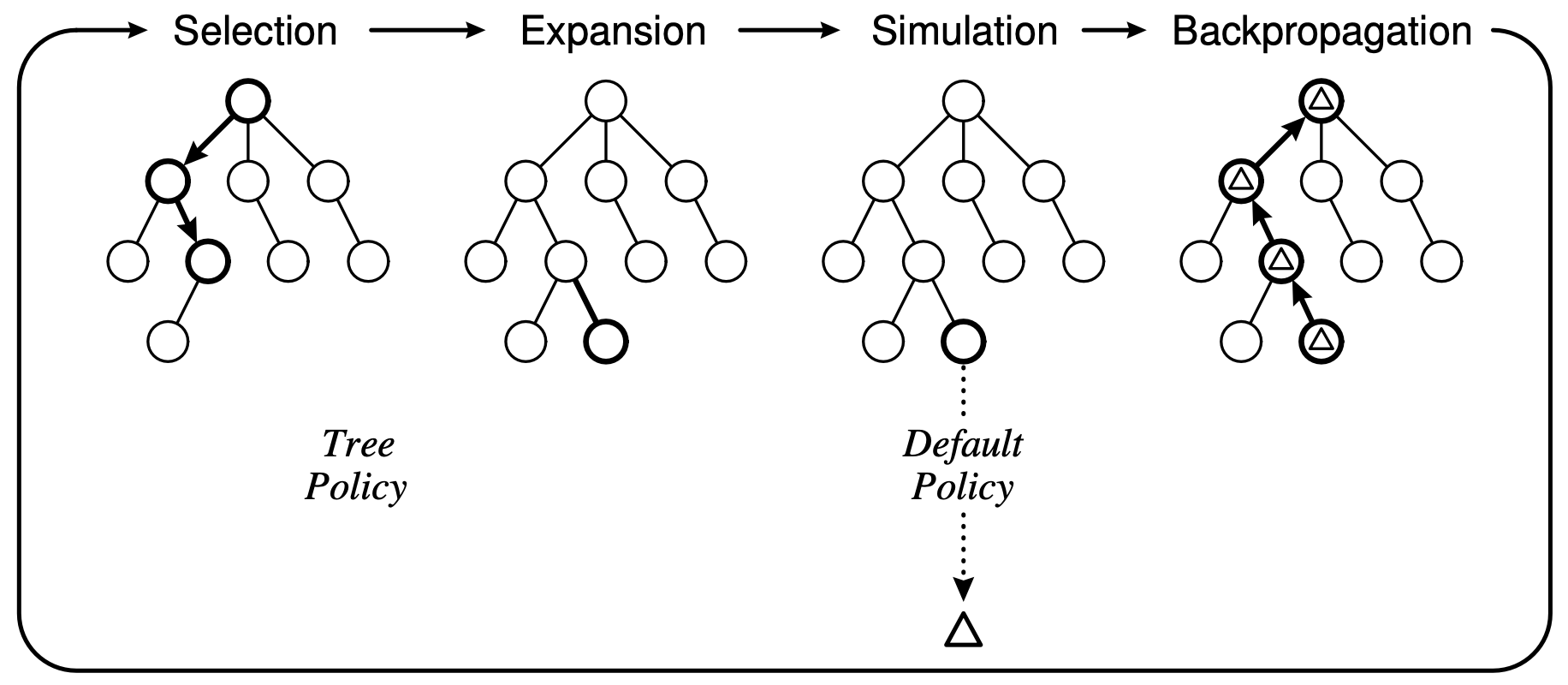
如上图,我们以围棋为例,在某个游戏节点(圆圈)下,有不同的走法(分支),将游戏进行到下一步,所以整个围棋游戏,完全可以用一个树状结构来表示。我们在下棋的时候,往往衡量一个人棋艺一个标准是看他能往前看几步,对应到树状结构中,就代表着树的深度;另外我们还会考察棋手的对棋局的考虑是否全面,所有的可能是否都考虑到位,对应这里就是树的广度(分支的数目)。
下面我们对照这个图,直奔算法:
- Selection: 从根节点开始,我们用Tree Policy来递归的选择分支,直到抵达某个未完全展开的非终止节点。所谓未完全展开的非终止节点是指,它至少有一个从未被访问过的子节点,且它自身不能是游戏结束的节点。
- Expansion: 在第一步,我们抵达的节点有未被访问的子节点,那么这一步的目的就是访问这个子节点。
- Simulation: 这时我们到达一个从未被访问的节点,从这一节点开始,我们用Default Policy来递归的进行游戏,直到游戏结束。注意这里,用Default Policy进行游戏的时候,我们并不考虑分支的情况,即只看一步棋,且对Default Policy访问的节点不进行记录。
- Backpropagation: 在第三步,我们用Default Policy跑完游戏时,会得到一个输赢的结果,那么这个结果将会被沿着游戏路径传递到根节点,且会更新沿途节点的信息。
- 如果还有思考时间还没用完,回到1.
算法流程理解起来其实并不难,但是里面有三个关键信息需要展开讲。
1. Tree Policy
首先我们需要知道,对于每个节点,我们记录了以下信息:这个节点被访问过的次数,和这次访问中,用Default Policy跑赢的次数。我们用表示一个节点,代表的子节点,是一个非负的常数,Tree Policy用UCT(Upper Confidence Tree)来选择分支:
下面我们来试着理解这个公式。第一项,其实就是子节点赢的统计频率。第二项,因为对来说是相等的,那么这里,子节点访问次数越多,它被选中的权重越小。所以这里常数就很重要了,当 ,Tree Policy将优先选择赢的统计频率最高的子节点分支。当 时候,Tree Policy将优先选择被访问次数最少的子节点,也就是说,平衡着游戏的的exploration和exploitation。
很多人可能会不解,第二项为什么会有开方和对数。这就要从Hoeffding's Inequality说起了:
For i.i.d (independent identical distribution) random variables bounded by , the sample mean , for we have
翻译成汉语就是说,我们对随机变量进行次采样,的真实期望与我们的统计均值的差值大于的概率,小于。这个,即为所谓的confidence bound。
也就是说,节点统计胜率偏离真实胜率多过的概率,不大于。这就是Upper Confidence Bound的由来了。
2. Default Policy
MCTS 采用了一种比较蠢的办法来做simulation,就是随机选,相当于让两个对围棋一无所知的人在不违反棋规的情况下完成比赛决定胜负。这显然有待改进。
3. Update Rule
对围棋来说,结局无非是三种情况:胜、负、平,我们用来分别表示。从第二步被展开的子节点往上回溯,对沿途所有节点:
还有一点很重要,由于围棋是Two Player Zero Sum的游戏,游戏过程中两人轮流走棋,所以Tree Policy在对手走棋的时,应该用,也就是说,我们考虑的是最危险的对手,他的走法会使我们胜率尽量低。
看懂以上,再来看文献给出的伪代码就简单多了

Implementation
我们以井字棋为例,提供两份代码,第一份是我撸的,第二份摘抄自mcts.ai。
区别并不大,主要是我的代码有记忆功能,也就是每次搜索都接着前一次的搜索结果,而不是从头开始。但第二份代码更加简洁,写的也比我好,值得收藏。
我的代码:
import numpy as np
import random
class State:
checkers = []
for i in range(3):
row = []
col = []
for j in range(3):
col.append((i, j))
row.append((j, i))
checkers.append(row)
checkers.append(col)
checkers.append([(0, 0), (1, 1), (2, 2)])
checkers.append([(2, 0), (1, 1), (0, 2)])
def __init__(self, board=None):
self.board = board if board is not None else np.zeros((3, 3))
def actions(self):
rows, cols = np.where(self.board == 0)
return list(zip(rows, cols))
def is_winner(self, player):
for check in self.checkers:
if player == self.board[check[0]] == self.board[check[1]] == self.board[check[2]]:
return True
return False
def play(self, pos, player):
new_state = self.clone()
new_state.board[pos] = player
return new_state
def clone(self):
state = State()
state.board[:, :] = self.board[:, :]
return state
def tostring(self):
out = ""
for i in range(3):
out += " ".join([".XO"[int(x)] for x in self.board[i]])
out += '\n'
return out
def UCT(child, N, c):
return child.Q / child.N + c * np.sqrt(2 * np.log(N)/child.N)
class Node:
def __init__(self, state, parrent, last_move, last_player):
self.state = state
self.actions = state.actions()
self.is_winner = state.is_winner(last_player)
self.parrent = parrent
self.last_move = last_move
self.last_player = last_player
self.children = {}
self.N = 0
self.Q = 0
def tree_policy(self, c=1):
return max(self.children, key=lambda k: UCT(self.children[k], self.N, c))
def max_visit(self):
return max(self.children, key=lambda k: self.children[k].N)
def tostring(self):
out = f"Root: {self.Q}/{self.N}={self.Q/self.N*100:5.2f}\n"
if len(self.children) > 0:
for k, v in self.children.items():
out += f"{k}: {v.Q:3.0f}/{v.N:3.0f}/{v.Q/v.N:4.2f}/{np.sqrt(2 * np.log(self.N + 1)/v.N):4.2f}\n"
out += "\n"
return out
class MCTS:
def __init__(self, root, player):
self.root = root
self.player = player
def step(self, search_count, last_action):
if last_action is not None:
if last_action in self.root.children:
self.root = self.root.children[last_action]
self.root.parrent = None
else:
new_state = self.root.state.play(last_action, 3 - self.player)
self.root = Node(new_state, None, last_action, 3 - self.player)
if len(self.root.actions) > 0:
for cnt in range(search_count):
self.search()
else:
return None, False
print(self.root.state.tostring())
print(self.root.tostring())
print("=" * 50)
action = self.root.max_visit()
self.root = self.root.children[action]
self.root.parrent = None
return action, self.root.is_winner
def search(self):
node = self.root
player = self.player
# Selection
while True:
actions = node.actions
is_winner = node.is_winner
if len(actions) > 0 and len(actions) == len(node.children) and not is_winner:
action = node.tree_policy()
node = node.children[action]
else:
break
# Expansion
if len(actions) > 0 and not is_winner:
action = random.choice([a for a in actions if a not in node.children])
player = 3 - node.last_player
new_state = node.state.play(action, player)
new_node = Node(new_state, node, action, player)
node.children[action] = new_node
node = new_node
# Rollout
state = node.state.clone()
while True:
actions = state.actions()
is_winner = state.is_winner(player)
if len(actions) > 0 and not is_winner:
action = random.choice(actions)
player = 3 - player
state = state.play(action, player)
else:
break
# Backpropogation
if is_winner:
winner = player
else:
winner = None
while True:
node.N += 1
if winner == node.last_player:
delta = 1
elif winner is None:
delta = 0.5
else:
delta = 0
node.Q += delta
node = node.parrent
if node is None:
break
def main():
root1 = Node(State(), None, None, 2)
mcts1 = MCTS(root1, 1)
root2 = Node(State(), None, None, 1)
mcts2 = MCTS(root2, 2)
winner = None
action, is_winner = mcts1.step(search_count=200, last_action=None)
while True:
if action is not None and not is_winner:
action, is_winner = mcts2.step(search_count=200, last_action=action)
elif is_winner:
winner = 1
break
else:
break
if action is not None and not is_winner:
action, is_winner = mcts1.step(search_count=200, last_action=action)
elif is_winner:
winner = 2
break
else:
break
print(f"Game Over. Winner is {winner}")
if __name__ == '__main__':
main()
摘抄的代码:
from math import *
import random
class GameState:
""" A state of the game, i.e. the game board. These are the only functions which are
absolutely necessary to implement UCT in any 2-player complete information deterministic
zero-sum game, although they can be enhanced and made quicker, for example by using a
GetRandomMove() function to generate a random move during rollout.
By convention the players are numbered 1 and 2.
"""
def __init__(self):
self.playerJustMoved = 2 # At the root pretend the player just moved is player 2 - player 1 has the first move
def Clone(self):
""" Create a deep clone of this game state.
"""
st = GameState()
st.playerJustMoved = self.playerJustMoved
return st
def DoMove(self, move):
""" Update a state by carrying out the given move.
Must update playerJustMoved.
"""
self.playerJustMoved = 3 - self.playerJustMoved
def GetMoves(self):
""" Get all possible moves from this state.
"""
def GetResult(self, playerjm):
""" Get the game result from the viewpoint of playerjm.
"""
def __repr__(self):
""" Don't need this - but good style.
"""
pass
class OXOState:
""" A state of the game, i.e. the game board.
Squares in the board are in this arrangement
012
345
678
where 0 = empty, 1 = player 1 (X), 2 = player 2 (O)
"""
def __init__(self):
self.playerJustMoved = 2 # At the root pretend the player just moved is p2 - p1 has the first move
self.board = [0,0,0,0,0,0,0,0,0] # 0 = empty, 1 = player 1, 2 = player 2
def Clone(self):
""" Create a deep clone of this game state.
"""
st = OXOState()
st.playerJustMoved = self.playerJustMoved
st.board = self.board[:]
return st
def DoMove(self, move):
""" Update a state by carrying out the given move.
Must update playerToMove.
"""
assert move >= 0 and move <= 8 and move == int(move) and self.board[move] == 0
self.playerJustMoved = 3 - self.playerJustMoved
self.board[move] = self.playerJustMoved
def GetMoves(self):
""" Get all possible moves from this state.
"""
return [i for i in range(9) if self.board[i] == 0]
def GetResult(self, playerjm):
""" Get the game result from the viewpoint of playerjm.
"""
for (x,y,z) in [(0,1,2),(3,4,5),(6,7,8),(0,3,6),(1,4,7),(2,5,8),(0,4,8),(2,4,6)]:
if self.board[x] == self.board[y] == self.board[z]:
if self.board[x] == playerjm:
return 1.0
else:
return 0.0
if self.GetMoves() == []: return 0.5 # draw
assert False # Should not be possible to get here
def __repr__(self):
s= ""
for i in range(9):
s += ".XO"[self.board[i]]
if i % 3 == 2: s += "\n"
return s
class Node:
""" A node in the game tree. Note wins is always from the viewpoint of playerJustMoved.
Crashes if state not specified.
"""
def __init__(self, move = None, parent = None, state = None):
self.move = move # the move that got us to this node - "None" for the root node
self.parentNode = parent # "None" for the root node
self.childNodes = []
self.wins = 0
self.visits = 0
self.untriedMoves = state.GetMoves() # future child nodes
self.playerJustMoved = state.playerJustMoved # the only part of the state that the Node needs later
def UCTSelectChild(self):
""" Use the UCB1 formula to select a child node. Often a constant UCTK is applied so we have
lambda c: c.wins/c.visits + UCTK * sqrt(2*log(self.visits)/c.visits to vary the amount of
exploration versus exploitation.
"""
s = sorted(self.childNodes, key = lambda c: c.wins/c.visits + sqrt(2*log(self.visits)/c.visits))[-1]
return s
def AddChild(self, m, s):
""" Remove m from untriedMoves and add a new child node for this move.
Return the added child node
"""
n = Node(move = m, parent = self, state = s)
self.untriedMoves.remove(m)
self.childNodes.append(n)
return n
def Update(self, result):
""" Update this node - one additional visit and result additional wins. result must be from the viewpoint of playerJustmoved.
"""
self.visits += 1
self.wins += result
def __repr__(self):
return "[M:" + str(self.move) + " W/V:" + str(self.wins) + "/" + str(self.visits) + " U:" + str(self.untriedMoves) + "]"
def TreeToString(self, indent):
s = self.IndentString(indent) + str(self)
for c in self.childNodes:
s += c.TreeToString(indent+1)
return s
def IndentString(self,indent):
s = "\n"
for i in range (1,indent+1):
s += "| "
return s
def ChildrenToString(self):
s = ""
for c in self.childNodes:
s += str(c) + "\n"
return s
def UCT(rootstate, itermax, verbose = False):
""" Conduct a UCT search for itermax iterations starting from rootstate.
Return the best move from the rootstate.
Assumes 2 alternating players (player 1 starts), with game results in the range [0.0, 1.0]."""
rootnode = Node(state = rootstate)
for i in range(itermax):
node = rootnode
state = rootstate.Clone()
# Select
while node.untriedMoves == [] and node.childNodes != []: # node is fully expanded and non-terminal
node = node.UCTSelectChild()
state.DoMove(node.move)
# Expand
if node.untriedMoves != []: # if we can expand (i.e. state/node is non-terminal)
m = random.choice(node.untriedMoves)
state.DoMove(m)
node = node.AddChild(m,state) # add child and descend tree
# Rollout - this can often be made orders of magnitude quicker using a state.GetRandomMove() function
while state.GetMoves() != []: # while state is non-terminal
state.DoMove(random.choice(state.GetMoves()))
# Backpropagate
while node != None: # backpropagate from the expanded node and work back to the root node
node.Update(state.GetResult(node.playerJustMoved)) # state is terminal. Update node with result from POV of node.playerJustMoved
node = node.parentNode
# Output some information about the tree - can be omitted
if (verbose): print(rootnode.TreeToString(0))
else: print(rootnode.ChildrenToString())
return sorted(rootnode.childNodes, key = lambda c: c.visits)[-1].move # return the move that was most visited
def UCTPlayGame():
""" Play a sample game between two UCT players where each player gets a different number
of UCT iterations (= simulations = tree nodes).
"""
# state = OthelloState(6) # uncomment to play Othello on a square board of the given size
state = OXOState() # uncomment to play OXO
# state = NimState(15) # uncomment to play Nim with the given number of starting chips
while (state.GetMoves() != []):
print(str(state))
if state.playerJustMoved == 1:
m = UCT(rootstate = state, itermax = 1000, verbose = False) # play with values for itermax and verbose = True
else:
m = UCT(rootstate = state, itermax = 100, verbose = False)
print("Best Move: " + str(m) + "\n")
state.DoMove(m)
if state.GetResult(state.playerJustMoved) == 1.0:
print("Player " + str(state.playerJustMoved) + " wins!")
elif state.GetResult(state.playerJustMoved) == 0.0:
print("Player " + str(3 - state.playerJustMoved) + " wins!")
else: print("Nobody wins!")
if __name__ == "__main__":
""" Play a single game to the end using UCT for both players.
"""
UCTPlayGame()