我们前面提到的蒙特卡洛树搜索,其实颇有强化学习的影子。而接下来我们会看到,learning和searching在解决问题上的共通和不同之处,以及他们融合之后的强大。
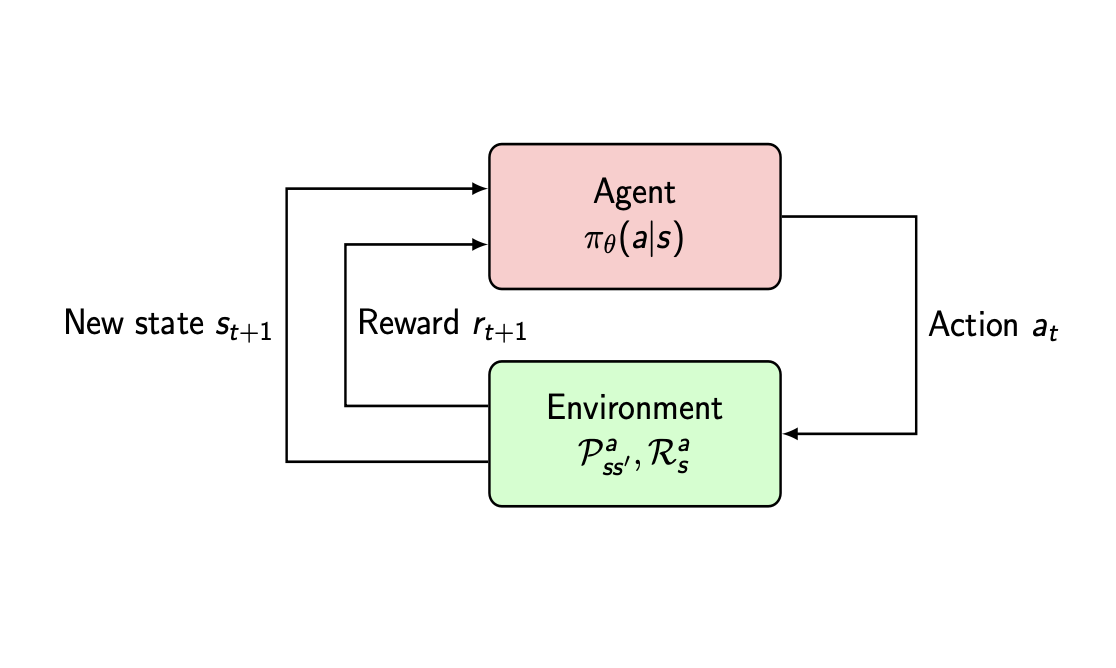
我们常说的强化学习包含两个要素:Agent和Environment。而学习的目标是指,Agent学到一个优秀的策略,使之与Environment互动中,获取更多的Reward;这个过程,就很像生物与环境的互动了。
Reinforcement Learning and Optimal Control
强化学习的数学模型脱胎于最优控制Optimal Control,我们甚至会发现,他们不过是同一问题的不同表述,以至于他们的数学形式都非常相似:
Reinforcement Learning:
maximize subject toEτ∼π{t=0∑Nγtrt+1}rt+1∼R(st,at)at∼π(a∣st)st+1∼P(st,at)τ=s0,a0,r1,s1,a1,r2… Optimal Control:
minimize subject toEτ∼π{k=0∑Ngk(xk,uk)}xk+1=fk(xk,uk)uk=πk(xk)τ=x0,u0,x1,u1,…
在optimal control的框架内,system dynamics和control policy往往被近似为linear或者quadratic的form,如此,在某个time-step下,该问题就是简单的convex optimisation的问题;再套用dynamic programming,从k=N求解到k=0,即可求得所有的control signal u0,u1,…,uN−1,亦即control policy π。
而在reinforcement learning的框架内,system dynamics和control policy更多是non-deterministic且non-linear的,亦或是未知的,套用optimal control的方法往往会面临诸多困难。所以,RL发展出了另一套基于Markov Decision Process的数学框架。
Markov Decision Process
作为RL的理论基础:
A Markov Decision Process is a 4 tuple (S,A,R,P) where:
- S is the set of state space
- A is the set of action space
- R is reward function: R:S×A→R
- P is transition probability: P:S×A×S→[0,1]
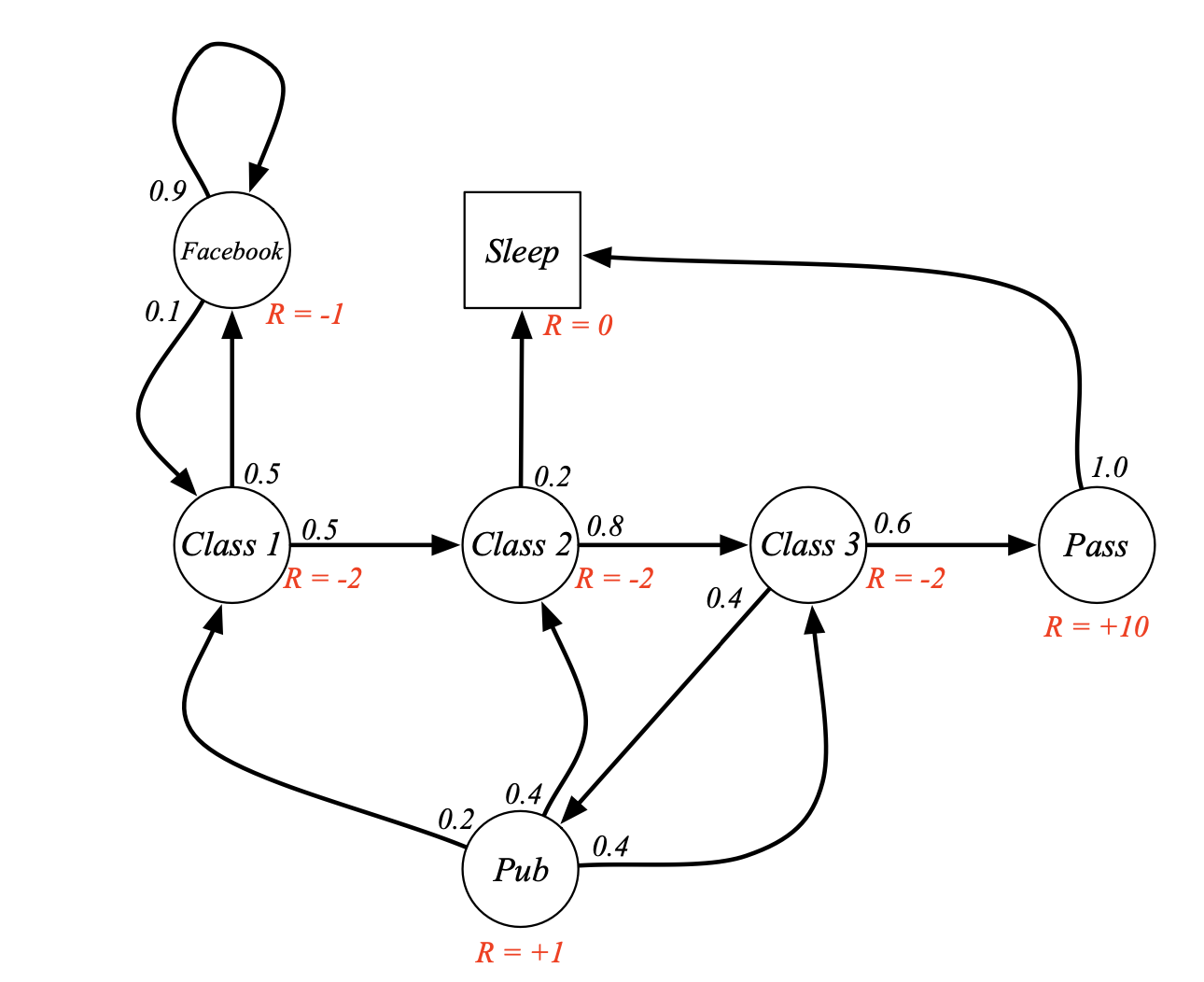
下图摘采自David Silver的lecture notes,图节点代表states,箭头代表state transition probability,相比于图中MDP,RL在应用层面的MDP往往要复杂的多:
- State/Action space is high dimensional/continous/finite
- Reward function is non-deterministic
在做RL理论研究时,为了简化问题,往往会将state space和action space设计为finite and discrete,reward function为deterministic,这种设计称之为tabular solution。对于上图所示给定策略的MDP,P为∣S∣×∣S∣的probabililty tensor,R为∣S∣的向量:
P=C100000.20.10C20.50000.400C300.8000.400Pass000.60000Pub000.40000FB0.500000.90Sleep00.201001 R=C1−2C2−2C3−2Pass10Pub1FB−1Sleep0 如何评价某个状态的好坏?我们以Pub为例,从此状态开始采样轨迹:
τ1τ2τ3=Pub,C1,C2,C3,Pass,Sleep=Pub,C2,Sleep=Pub,C3,Pub,C1,FB,C1,C2,Sleep… 计某个轨迹的累积奖励为G,那么
G(τ1)G(τ2)G(τ3)=+1−2−2−2+10+0=+1−2+0=+1−2+1−2−1−2−2+0… 那么Pub的平均累计奖励
V(spub)=NG(τ1)+G(τ2)+G(τ3)+⋯+G(τN) 即可作为评估其好坏的指标。若是已知V(sC1),V(sC2),V(sC3),又有:
V(spub)=1+0.2×V(sC1)+0.4×V(sC2)+0.4×V(sC3) 对于以上MDP,已知P,R,对于求出V显然是完备的,具体来说:
V=R+PVV=(I−P)−1RT Reinforcement Learning
对于RL,我们再定义
RL Basis
- Policy function π:S×A→[0,1]
- Value function V:S→R
- Discount factor γ∈(0,1]
- Episodic trajectory τ=(s0,a0,r1,s1,a1,r2,…) where s0∼d0(s),a0∼π(s0),r1∼R(s0,a0),s1∼P(s0,a0),…
- Discounted return G(τ)=r1+γr2+γ2r3+⋯=∑t=0Tγtrt+1
我们注意到,如果γ∈(0,1)的话,G(τ)≤rmax/(1−γ),可见,discounted factor作用是使得discounted return bounded。
RL的优化目标为寻找最优策略:
π∗=πmaxEτ∼π[G(τ)] 为此,大致衍生出两种解法,一种是直接take gradient的policy gradient,一种是基于值函数的TD learning;而两者之混合产生了更为优秀的解法,称之为actor critic。
Policy Gradient Method
PG的数学稍微有点意思:
我们定义某个策略π的expected total discounted return
η(π)=Eτ∼π[G(τ)]=∫τ∈T(π)p(τ)G(τ)dτ 其中T(π)为所有轨迹的集合。对于某个采样到的episodic trajectory τ=(s0,a0,r1,s1,a1,r2,…)
p(τ)=d(s0)t=0∏Tπ(st,at)P(st,at,st+1)G(τ)=t=0∑Tγtrt+1 对于带有参数的策略πθ,我们求其梯度
∇θη(πθ)=∫∇θpθ(τ)G(τ)dτ=∫pθ(τ)∇θlogpθ(τ)G(τ)dτ=∫pθ(τ)∇θ[logd(s0)+t=0∑Tlogπθ(st,at)+t=0∑TlogP(st,at,st+1)]G(τ)dτ=∫pθ(τ)t=0∑T∇θlogπθ(st,at)G(τ)dτ=Eτ∼pθ(τ)[(t=0∑T∇θlogπθ(st,at))(t=0∑Tγtrt+1)] 依此,即可得到经典的REINFORCE算法:
REINFORCE Algorithm
- Sample episodic trajectory {τi} from πθ(s,a)
- Calculate ∇θη(πθ)≈∑i(∑t∇θlogπθ(si,t,ai,t))(∑tγtri,t+1))
- Update policy θ←θ+α∇θη(πθ)
Value Function Method
我们定义值函数
Vπ(s)=Eτ∼π,s0=s[G(τ)] 即:以s为起始状态,π为采样策略的episodic trajectory的discounted return的期望值。由此
Vπ(s)=Ea∼π[R(s,a)+γGt+1∣St=s]=a∈A∑π(s,a)s′∈S∑p(s′∣s,a)[r(s,a)+γVπ(s′)]=a∈A∑π(s,a)r(s,a)+γa∈A∑s′∈S∑p(s′∣s,a)π(s,a)Vπ(s′) 我们定义Q函数
Qπ(s,a)=Eτ∼π,s0=s,a0=a[G(τ)] 即:以s为起始状态,a为起始动作,π为采样策略的episodic trajectory的discounted return的期望值。由此
Qπ(s,a)=r(s,a)+γs′∈S∑p(s′∣s,a)Vπ(s′) 我们很容易得出
Vπ(s)=a∈A∑π(s,a)Qπ(s,a) Qπ(s,a)=r(s,a)+γs′∈S∑p(s′∣s,a)a′∈A∑π(s′,a′)Qπ(s′,a′) 我们称上面两个公式为Bellman Equations for on-policy value function。
对于最优策略π∗, 其对应的optimal solution
V∗(s)=amaxQ∗(s,a)=amaxs′∈S∑p(s′∣s,a)[r(s,a)+γV∗(s′)] Q∗(s,a)=r(s,a)+γs′∈S∑p(s′∣s,a)V∗(s′)=r(s,a)+γs′∈S∑p(s′∣s,a)a′maxQ∗(s′,a′) 我们称上面两个公式为Bellman Optimal Equations 。
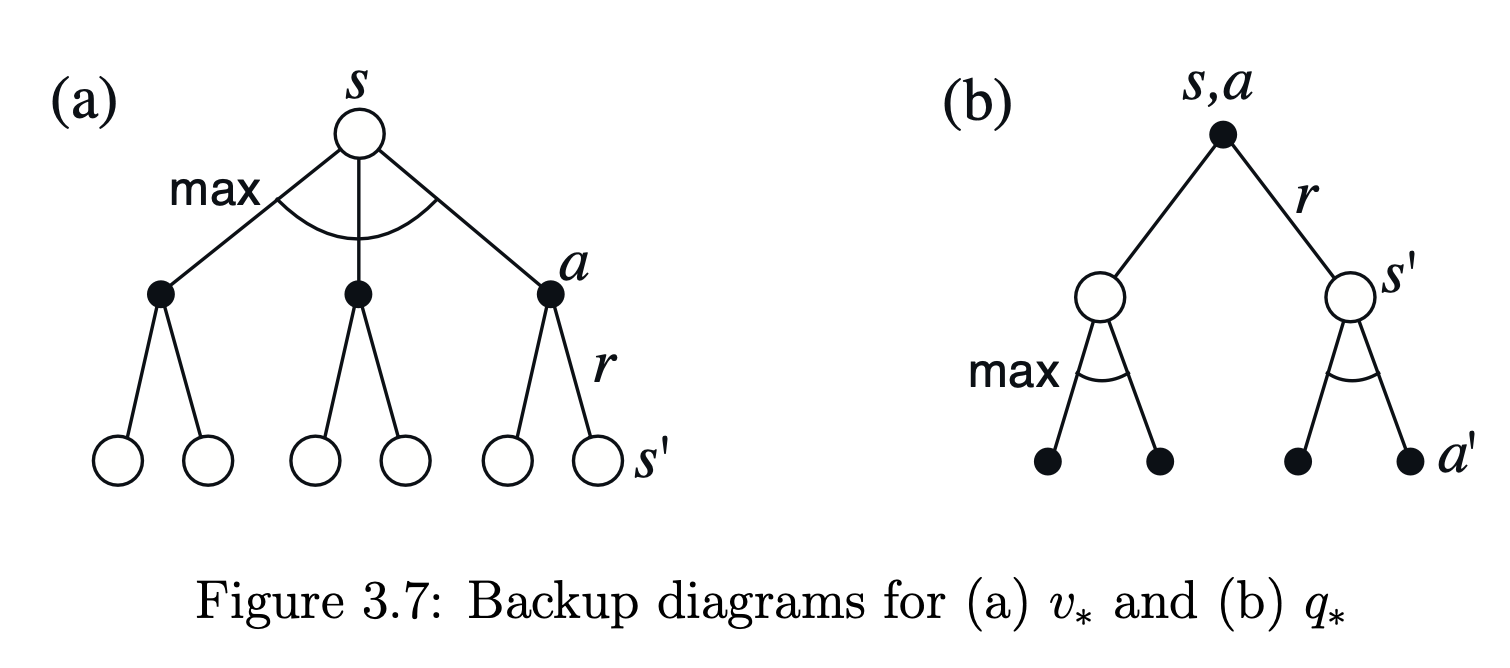
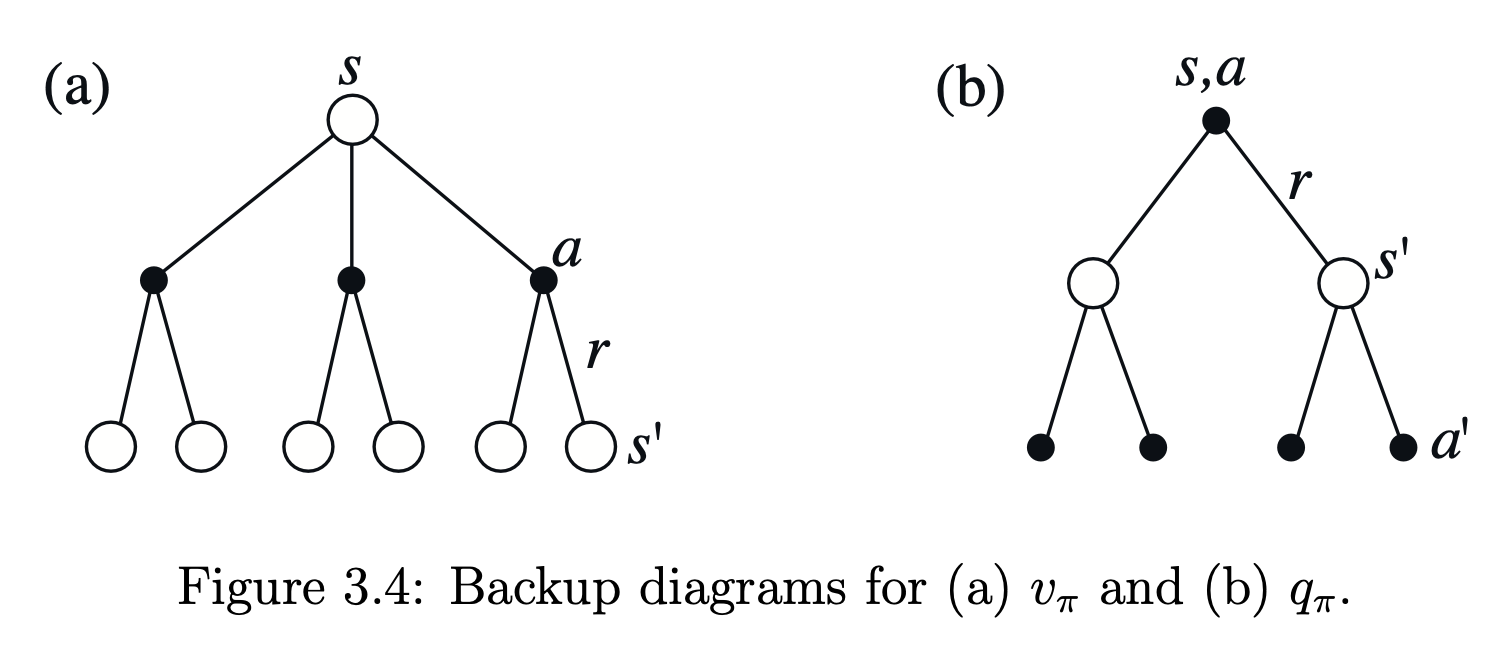
借用Sutton的的书中第三章的图,以描述Q函数和值函数及其opitmal solution
看到这两张图,应该会想起MCTS的吧~
下面我们给出Value Iteration算法:
Value Iteration:
- Randomly initialise V(s)
- Δ←0, for each s∈S:
v←V(s)V(s)←amaxs′∈S∑p(s′∣s,a)[r(s,a)+γV∗(s′)]Δ=max(Δ,∣v−V(s)∣)> - Repeat step 2 until Δ is sufficient small
- Output policy π(s)=argmaxa∑s′∈Sp(s′∣s,a)[r(s,a)+γV∗(s′)]
我们注意到,VI算法的缺点在于需要知道model的transition probability p(s′∣s,a);而现实中,很多问题的model并不available,这种情况下,我们只好进行估算,比如Monte Carlo Control:
Monte Carlo Control:
- Randomly initialize π(s),Q(s,a), create a list dictionary R(s,a)
- Loop for each episode:
- Generate trajectory s0,a0,r1,s1,a1,…,sT with a∼π(s), G←0
- For timestep t=T−1,T−2,…,0:
- G←γG+rt+1
- Append G to R(st,at)
- Q(st,at)=∑R(st,at)/∣R(st,at)∣
- π(st)=argmaxaQ(st,a)
我们看到Monte Carlo Control 本质上是在通过采样的方法估算Q函数:
Q∗(s,a)=Eτ∼π∗,s0=s,a0=a[G(τ)]≈N1(G(τ1)+G(τ2)+⋯+G(τN))whereτn∼π∗withs0=s,a0=a 更进一步,我们可以
Q∗(s,a)=r(s,a)+γEs′[a′maxQ(s′,a′)]≈r(s,a)+γN1(a′maxQ(s1′,a′)+a′maxQ(s2′,a′)+⋯+a′maxQ(sN′,a′)) 依此,给出Q Learning 算法
Q Learning:
- Randomly initialise Q(s,a), ϵ-greedy policy πQ, learning rate α
- Loop for each episode:
- For each time-step t:
- t∼πQ(s)
- Q(st,at)←Q(st,at)+α[rt+1+γmaxaQ(st+1,a)−Q(st,at)]
所谓的ϵ-greedy policy:
π(s)={a∼A/a∗,x≥ϵa∗,x<ϵwherea∗=argamaxQ(s,a),x∼[0,1] 在estimate maxa′Q(s′,a′)的时候,我们用exponential running average代替了原本的mean,因为我们认为,随着learning的继续,我们的optimal Q estimation会越来越接近真实值。
Actor Critic Method
我们之前提到的REINFORCE算法在实际应用中,会存在很大问题:
- 样本利用率过低。采样N个trajectory,policy才更新一次;相对于单个元组<s,a,r>即可更新的Q learning,对数据的利用率太低。
- 梯度噪音过大。如果environment够丰富的话,相对于整个轨迹空间,采样到的轨迹的分布的覆盖率可能微乎其微,甚至过于集中,这样得到的梯度偏差非常大,以至于下次采样得到的轨迹分布更加不均匀,陷入恶性循环,导致学习失败。
- Return的分布问题。如果environment的reward全是非负,或者非正,那么gradient的方向便是一边倒,如果policy用的是neural network,则很容易出现数值溢出的问题,导致学习失败。
对于问题3,我们取一个baseline,
b=N1i=1∑NG(τi) 让每一个trajectory的return减去这个baseline以区分不同trajectory的偏向,我们发现policy gradient
∇θη(πθ)=∫∇θpθ(τ)(G(τ)−b)dτ=∫∇θpθ(τ)G(τ)dτ−∫∇θpθ(τ)bdτ=∫∇θpθ(τ)G(τ)dτ−b∇θ∫pθ(τ)dτ=∫∇θpθ(τ)G(τ)dτ−b∇θ1=∫∇θpθ(τ)G(τ)dτ 并没有被影响到。
对于问题1,我们很容易想到用experience replay的办法来解决,即:我们将采集到的<s,a,r>元组放在一个fixed size pool中,每次更新,从里面随机抽取一部分元组求梯度即可。接下来,我们考虑单个元组对policy gradient的贡献:
Eτ∼pθ′(τ)[∇θlogπθ(st,at)G(τ)] 这里又涉及到两个问题:
- Causality的问题。从因果关系上讲,π(st,at)影响不了已经发生的∑t′=0tγt′rt′+1。从梯度区分度上讲,在同一个trajectory中,不同的元组,对梯度的偏向权重相同,都是G(τ)=∑tγtrt+1。
- Off-policy的问题。我们注意到,使用experience replay,会导致更新policy用的经验,可能并不是当前待更新的policy产生的,这与我们推导出的policy gradient的要求不符。
对于causality的问题,我们考虑用Q(st,at)来代替G(τ)来解决。这种情况下,我们用V(st)做为baseline以区分gradient偏向,我们定义advantage function A(st,at)=Q(st,at)−V(st)=rt+γV(st+1)−V(st),那么单个元组对policy gradient的贡献为
∇θη(πθ)=Eτ∼pθ′(τ)[∇θlogπθ(st,at)A(st,at)] 对于off-policy的问题,考虑importance sampling
Ex∼p(x)[f(x)]=∫p(x)f(x)dx=∫p(x)q(x)p(x)f(x)dx=∫q(x)q(x)p(x)f(x)dx=Ex∼q(x)[q(x)p(x)f(x)] Importance Sampling的意义是,如果我们的数据x是从q(x)分布采样获得,而我们要计算f(x)在p(x)分布下的期望,应该如何转换。那么对于off-policy,
∇θη(πθ)=∇θEτ∼pθ(τ)[G(τ)]=∇θEτ∼pθ′(τ)[pθ′(τ)pθ(τ)G(τ)] 注意到
pθ′(τ)pθ(τ)=p(s0)∏tπθ′(st,at)p(st+1∣st,at)p(s0)∏tπθ(st,at)p(st+1∣st,at)=∏tπθ′(st,at)∏tπθ(st,at) 如此,我们得到修正后的policy gradient
∇θη(πθ)=Eτ∼pθ′(τ)[πθ′(st,at)πθ(st,at)∇θlogπθ(st,at)A(st,at)]≈N1i=1∑N πθ′(st,i,at,i)πθ(st,i,at,i)∇θlogπθ(st,i,at,i)A(st,i,at,i) 以上即是Actor Critic的理论基础;据此,我们写出Offline Actor Critic算法:
Offline Actor Critic:
- Randomly initialise policy network πθ and value network Vϕ, an empty replay buffer R
- Loop for each trajectory:
Loop for each time-step t:
- Sample <st,at,rt> from πθ, record π^t=πθ(st,at)
- Periodically update, if tmodT=0, sample a batch of N tuples {si,ai,π^i,ri,si′,gi}, calculate:
- Advantage Function A(si,ai)=ri+γVϕ(si′)−Vϕ(si)
- Policy Gradient ∇θη(πθ)=N−1∑iπ(si,ai)∇θlogπθ(si,ai)A(si,ai)/π^i
- Value Gradient Δϕ=N−1∑i∇ϕ(Vϕ(si)−gi)2
- Update policy network: θ←θ+α∇θη(πθ)
- Update value network: ϕ←ϕ−βΔϕ
Calculate discounted sum rewards: gt=rt+γrt+1+γ2rt+2+…
for each timestep, and push <st,at,π^t,rt,st+1,gt> into replay buffer R
SuttonBartoIPRLBook2ndEd.pdf