有了的理论基础,再看第二部分,就会简单很多。所谓的Deep Reinforcement Learning,无非是Deep Neural Network和Reinforcement Learning的结合,也就是用DNN作为Value Estimator和Policy Function。有了DNN的加持,我们发现RL在很多问题上的表现有了质的飞跃。
在所有机器学习算法中,DRL最接近于生物大脑的学习方式(除了Backpropagation);在与人类智力较量的棋牌电竞等游戏中,横扫人类最顶尖的选手,可以说是相当震撼,引用职业九段围棋选手段柯洁的话说:
人类数千年的实战演练进化,计算机却告诉我们人类全都是错的。我觉得,甚至没有一个人沾到围棋真理的边。
DQN可谓是DRL的开山之作,发表于2013年的NIPS;稍作修改后,即在2015年投向Nature,这篇 也是较早出圈,投中顶级学术期刊的文章之一。
最原始的版本称之为DQN ,算法如下:
DQN Algorithm
Initialise Q network Q θ Q_\theta Q θ Q θ ′ Q_{\theta'} Q θ ′ R \mathcal{R} R C C C For each episode:For each time-step t t t Use ϵ \epsilon ϵ a t a_t a t Q θ ( s t ) Q_\theta(s_t) Q θ ( s t ) s t + 1 s_{t+1} s t + 1 r t r_t r t d t d_t d t < s t , a t , r t , d t , s t + 1 > <s_t, a_t, r_t, d_t, s_{t+1}> < s t , a t , r t , d t , s t + 1 > R \mathcal{R} R
Periodically update, if t m o d T = 0 t\bmod T = 0 t mod T = 0 N N N { s i , a i , r i , d i , s i ′ } \{s_i, a_i, r_i, d_i, s_i'\} { s i , a i , r i , d i , s i ′ }
Target Q value q i = r i + γ ( 1 − d i ) max a ′ Q θ ′ ( s i ′ , a ′ ) q_i = r_i + \gamma(1-d_i)\max_{a'}Q_{\theta'}(s_i', a') q i = r i + γ ( 1 − d i ) max a ′ Q θ ′ ( s i ′ , a ′ ) TD Error loss L ( θ ) = N − 1 ∑ i ( Q θ ( s i ) − q i ) 2 L(\theta) = N^{-1}\sum_i(Q_\theta(s_i) - q_i)^2 L ( θ ) = N − 1 ∑ i ( Q θ ( s i ) − q i ) 2 Update Q network: θ ← θ − α ∇ θ L ( θ ) \theta \leftarrow \theta - \alpha \nabla_\theta L(\theta) θ ← θ − α ∇ θ L ( θ )
Periodically update, if t m o d T ′ = 0 t \bmod T' = 0 t mod T ′ = 0
synchronise target Q network θ ′ ← θ \theta' \leftarrow \theta θ ′ ← θ
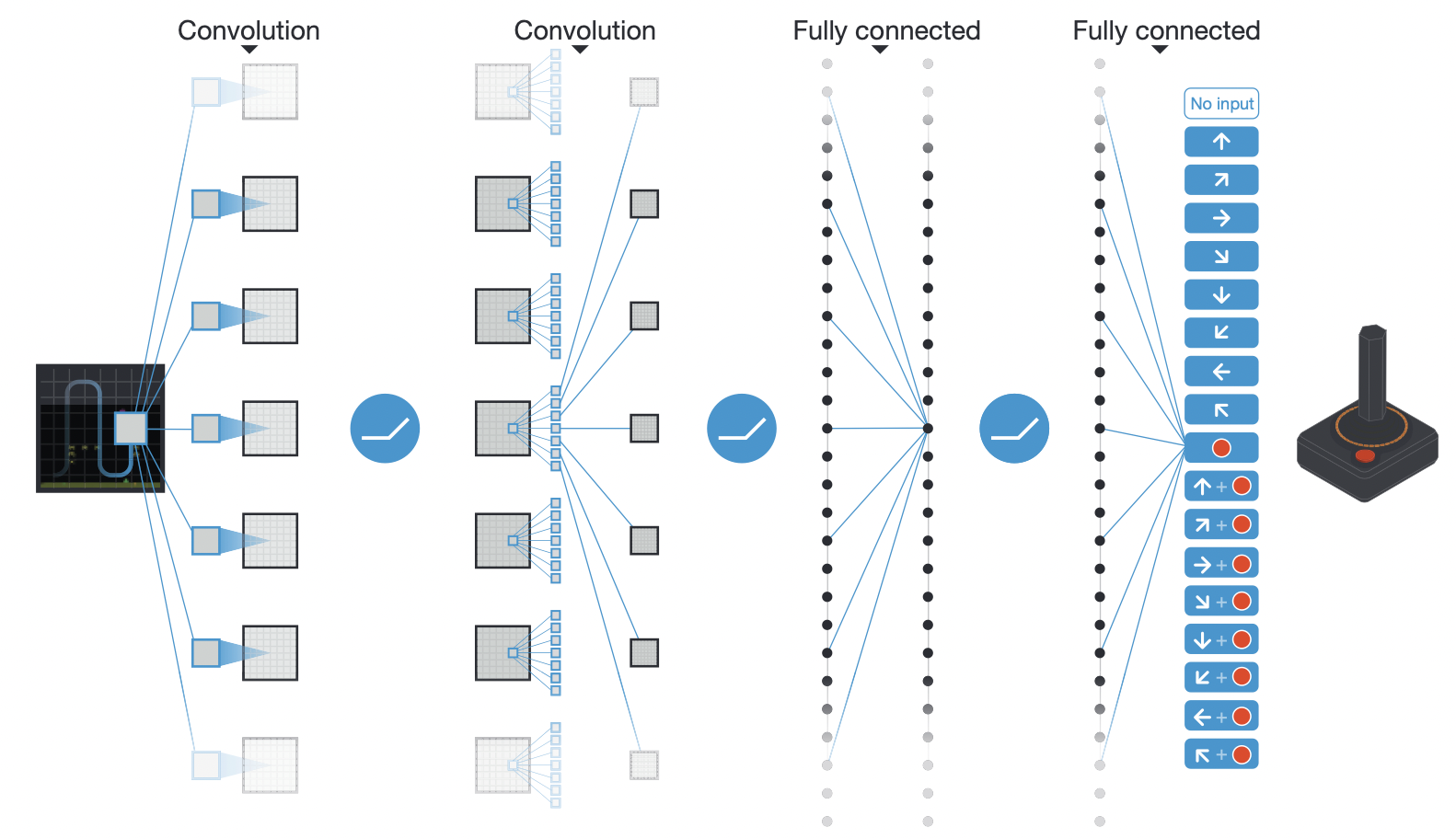
文章用的DNN其实并不深,只有两层convolution和两层dense,只是参数数量相对很久之前的作品较大:
在算法上,我们注意到DQN用了两个网络:一个policy Q network用来算Q值,一个target Q network用来算目标Q值且周期性与policy Q network同步。文中解释用两个网络的原因是为了减少在计算TD Error时Bellman Equation两边的相关性。文中指出,s t s_t s t s t s_t s t s t + 1 s_{t+1} s t + 1 s t + 1 s_{t+1} s t + 1 s t s_t s t
另外,文中没有提到的是,在计算TD Error Loss的时候,作者使用的是smooth版的L2 Loss,也被称之为Huber Loss:
L δ ( x ) = { x 2 / 2 , ∣ x ∣ < 1 ∣ x ∣ , ∣ x ∣ ≥ 1 L_\delta(x) = \begin{cases} x^2/2, |x| < 1 \\ |x|, |x| \geq 1 \end{cases} L δ ( x ) = { x 2 /2 , ∣ x ∣ < 1 ∣ x ∣ , ∣ x ∣ ≥ 1 显然max ∇ x L δ = 1 \max \nabla_x L_\delta = 1 max ∇ x L δ = 1
第三,算法使用了RMS-prop optimiser来计算gradient。其目的在于,对gradient进行element-wise normalisation,使得在training过程中gradient不至于过大或者过小,而导致学习失败。
通过以上三点,我们注意到,DQN算法对稳定性要求极高,对超参特别敏感。原因是什么呢?我认为是RL学习样本的特殊性。在DNN普通分类任务的学习中,一般来说样本是均匀分布(Uniform Distribution)的,因此每个batch的样本都具有相当高的随机一致性,这也使得每一次计算的gradient都具有相当高的可信度;而RL的任务中,因为reward的稀疏性,在一个batch中,只有少数样本有reward信息(大部分reward为0),甚至有些batch毫无reward信息,这就使得这个batch算出的gradient的可信度并不高,如果gradient过大,会直接让使用ϵ \epsilon ϵ
在DQN算法中,我们使用Bellman Optimal Equation来计算TD Error:
Q ( s , a ) = r ( s , a ) + γ max a ′ Q ( s ′ , a ′ ) Q(s, a) = r(s, a) + \gamma \max_{a'}Q(s', a') Q ( s , a ) = r ( s , a ) + γ a ′ max Q ( s ′ , a ′ ) 在对Q ( s ′ , a ′ ) Q(s', a') Q ( s ′ , a ′ ) Q ( s ′ , a ′ ) Q(s',a') Q ( s ′ , a ′ ) max a ′ Q ( s ′ , a ′ ) \max_{a'} Q(s',a') max a ′ Q ( s ′ , a ′ ) Q ( s , a ) Q(s,a) Q ( s , a ) Q ( s , a ) Q(s,a) Q ( s , a )
为了对抗这种高估,Double DQN 使用如下公式:
Q θ ( s , a ) = r ( s , a ) + γ Q θ ′ ( s ′ , arg max a ′ Q θ ( s ′ , a ′ ) ) Q_{\theta}(s, a) = r(s, a) + \gamma Q_{\theta'}(s', \arg\max_{a'}Q_\theta(s', a')) Q θ ( s , a ) = r ( s , a ) + γ Q θ ′ ( s ′ , arg a ′ max Q θ ( s ′ , a ′ )) 相比于DQN算法中计算TD Error的公式:
Q θ ( s , a ) = r ( s , a ) + γ max a ′ Q θ ′ ( s ′ , a ′ ) Q_\theta(s, a) = r(s, a) + \gamma \max_{a'}Q_{\theta'}(s', a') Q θ ( s , a ) = r ( s , a ) + γ a ′ max Q θ ′ ( s ′ , a ′ ) double DQN在求optimal action时使用的是policy network,而据此action取optimal value时却使用的是target network。如果DNN对Q ( s ′ , a ′ ) Q(s',a') Q ( s ′ , a ′ )
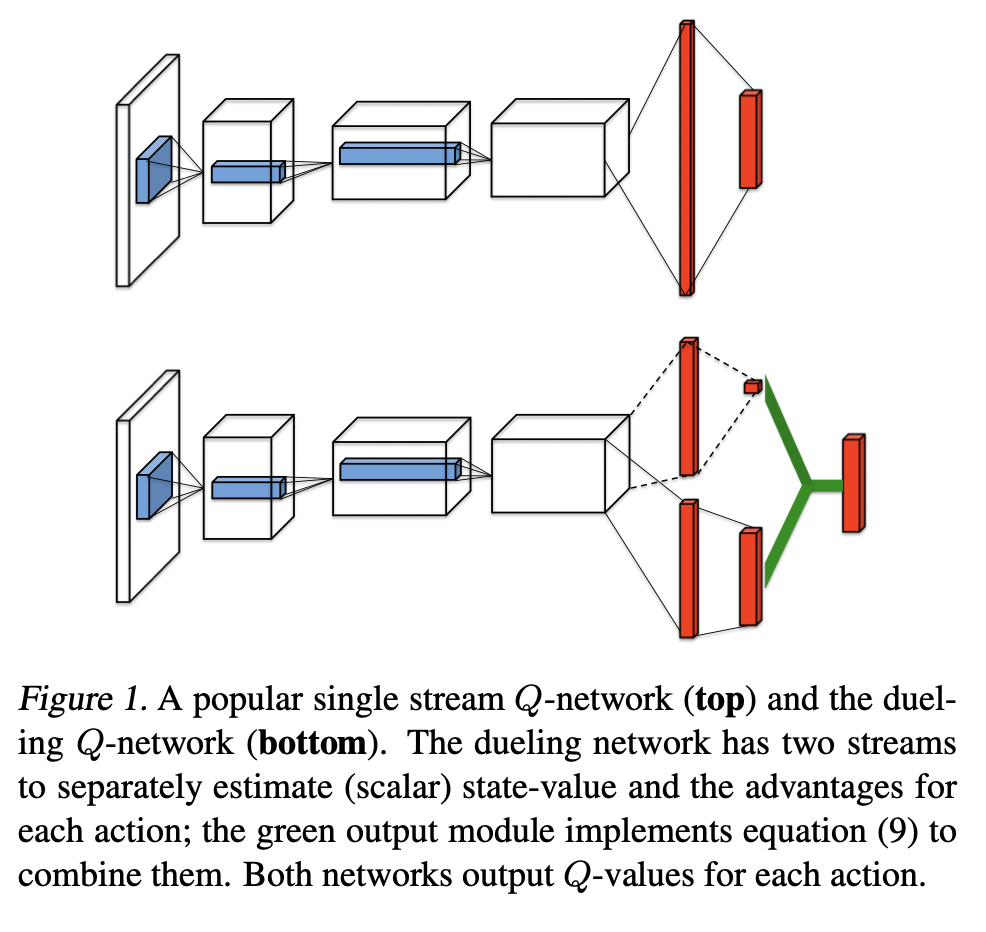
Dueling DQN 考虑从网路结构方面解决这一问题:
相对于DQN的网络,Dueling DQN的网络在结尾有两个stream,最后合并为一个head,对应的公式如下:
Q ( s , a ) = V ( s ) + A ( s , a ) − max a ′ A ( s , a ′ ) Q(s, a) = V(s) + A(s, a) - \max_{a'} A(s, a') Q ( s , a ) = V ( s ) + A ( s , a ) − a ′ max A ( s , a ′ ) 对应到上图中bottom的network,uppper stream是V ( s ) V(s) V ( s ) A ( s , a ) A(s, a) A ( s , a ) A ( s , a ) ≤ max a ′ A ( s , a ′ ) A(s,a) \leq \max_{a'}A(s,a') A ( s , a ) ≤ max a ′ A ( s , a ′ ) Q ( s , a ) ≤ V ( s ) Q(s,a) \leq V(s) Q ( s , a ) ≤ V ( s ) Q ( s , a ) Q(s,a) Q ( s , a ) max a ′ Q ( s ′ , a ′ ) \max_{a'} Q(s', a') max a ′ Q ( s ′ , a ′ )
Dueling DQN在实验中给出计算Q ( s , a ) Q(s,a) Q ( s , a )
Q ( s , a ) = V ( s ) + A ( s , a ) − 1 ∣ A ∣ ∑ a ′ ∈ A A ( s , a ′ ) Q(s, a) = V(s) + A(s, a) - \frac{1}{|\mathcal{A}|}\sum_{a' \in \mathcal{A}} A(s, a') Q ( s , a ) = V ( s ) + A ( s , a ) − ∣ A ∣ 1 a ′ ∈ A ∑ A ( s , a ′ ) 而且给出了基础attention map的解释:
如上图,作者认为,value stream和advantage stream的saliency map不同,代表两个stream分别attend到不同的content,从而实现更好的performance,对于这种sample based explanation,我只能持保留意见。不过,作者在文中给出的另一种解释倒是挺有意思:
Furthermore, the differences between Q-values for a given state are often very small relative to the magnitude of Q. For example, after training with DDQN on the game of Seaquest, the average action gap (the gap between the Q values of the best and the second best action in a given state) across visited states is roughly 0.04, whereas the average state value across those states is about 15. This difference in scales can lead to small amounts of noise in the up- dates can lead to reorderings of the actions, and thus make the nearly greedy policy switch abruptly.
主要是讲,Double DQN输出的Q ( a ; s ) Q(a;s) Q ( a ; s )
Prioritised Experience Replay 这篇文章的思路很简单,文章针对的问题,还是RL的reward的稀疏性所带来loss不稳定性。我们回忆下Bellman Optimal Equation
Q ( s , a ) = r ( s , a ) + γ max a ′ Q ( s ′ , a ′ ) Q(s, a) = r(s, a) + \gamma\max_{a'}Q(s', a') Q ( s , a ) = r ( s , a ) + γ a ′ max Q ( s ′ , a ′ ) 因为reward的稀疏性,大部分的情况下r ( s , a ) = 0 r(s,a)=0 r ( s , a ) = 0 Δ = Q θ ( s , a ) − γ max a ′ Q θ ′ ( s ′ , a ′ ) \Delta =Q_\theta(s, a) - \gamma \max_{a'}Q_{\theta'}(s', a') Δ = Q θ ( s , a ) − γ max a ′ Q θ ′ ( s ′ , a ′ ) r ( s , a ) ≠ 0 r(s, a) \neq 0 r ( s , a ) = 0
相应的,loss较小的样本,对应的gradient就会小,对训练过程的贡献就不大,而这部分样本又占了replay中的多数,如果随机采样的话,就会拖慢学习速度。至此,文章的思路就呼之欲出了:
改变随机采样的策略,让样本被采样到的概率与其对应TD error正相关。
因为replay buffer的size都是million级别的,如果采用一般的sampling函数,会导致采样非常缓慢,作者给出的解决方案是使用segment tree 。然而,如果cuda升级到了11.0之后,用GPU采样的话,就没有以上问题了。我们知道,在training早期,DNN给出的Q value approximation的error是很大的,这会让error较大的样本更容易被采样到,为了平衡这个问题,作者用一个参数α \alpha α P ( i ) = e i α / ∑ k e k α P(i) = e_i^\alpha / \sum_k e_k^\alpha P ( i ) = e i α / ∑ k e k α α = 0 \alpha = 0 α = 0 α = 1 \alpha=1 α = 1 α = 0.5 \alpha = 0.5 α = 0.5
另外,因为replay buffer的采样策略的改变,会使我们据此算出的Q π ( s , a ) Q^\pi(s, a) Q π ( s , a ) w i = ( N P ( i ) ) − β w_i = (NP(i))^{-\beta} w i = ( NP ( i ) ) − β β = 1 \beta = 1 β = 1 β = 0 \beta = 0 β = 0 β \beta β
DQN及其变种主要针对的是discrete action space的情况。DDPG 这篇文章则是相似的算法,针对continuous action space的情况的适应:
DDPG Algorithm:
Randomly initialize Q netowrk Q θ ( s , a ) Q_\theta(s, a) Q θ ( s , a ) μ ϕ ( s ) \mu_\phi(s) μ ϕ ( s ) Q θ ′ , μ ϕ ′ Q_{\theta'}, \mu_{\phi'} Q θ ′ , μ ϕ ′ R \mathcal{R} R σ \sigma σ For each episode:For each time-step t t t Sample an action a t ∼ N ( μ ϕ ( s t ) , σ 2 ) a_t \sim \mathcal{N}(\mu_\phi(s_t), \sigma^2) a t ∼ N ( μ ϕ ( s t ) , σ 2 ) s t + 1 s_{t+1} s t + 1 r t r_t r t d t d_t d t < s t , a t , r t , d t , s t + 1 > <s_t, a_t, r_t, d_t, s_{t+1}> < s t , a t , r t , d t , s t + 1 > R \mathcal{R} R
Sample a batch of N N N { s i , a i , r i , d i , s i ′ } \{s_i, a_i, r_i, d_i, s_i'\} { s i , a i , r i , d i , s i ′ }
target Q value q i = r i + γ ( 1 − d i ) Q θ ′ ( s i ′ , μ ϕ ′ ( s i ′ ) ) q_i = r_i + \gamma (1-d_i)Q_{\theta'}(s_i', \mu_{\phi'}(s_i')) q i = r i + γ ( 1 − d i ) Q θ ′ ( s i ′ , μ ϕ ′ ( s i ′ ))
critic loss L ( θ ) = N − 1 ∑ i ( Q θ ( s i , a i ) − q i ) 2 L(\theta)=N^{-1}\sum_i(Q_\theta(s_i, a_i)- q_i)^2 L ( θ ) = N − 1 ∑ i ( Q θ ( s i , a i ) − q i ) 2
policy gradient: ∇ ϕ J ( ϕ ) = N − 1 ∑ i ∇ ϕ Q θ ( s i , μ ϕ ( s i ) ) \nabla_\phi J(\phi) = N^{-1}\sum_i \nabla_\phi Q_\theta(s_i,\mu_\phi(s_i)) ∇ ϕ J ( ϕ ) = N − 1 ∑ i ∇ ϕ Q θ ( s i , μ ϕ ( s i ))
Update Q network: θ ← θ − α ∇ θ L ( θ ) \theta \leftarrow \theta - \alpha \nabla_\theta L(\theta ) θ ← θ − α ∇ θ L ( θ )
Update policy network: ϕ ← ϕ + β ∇ ϕ J ( ϕ ) \phi \leftarrow \phi + \beta \nabla_\phi J(\phi) ϕ ← ϕ + β ∇ ϕ J ( ϕ )
Update target networks:
θ ′ ← τ θ ′ + ( 1 − τ ) θ ϕ ′ ← τ ϕ ′ + ( 1 − τ ) ϕ \theta' \leftarrow \tau\theta' + (1-\tau)\theta \\ \phi' \leftarrow \tau\phi' + (1-\tau)\phi θ ′ ← τ θ ′ + ( 1 − τ ) θ ϕ ′ ← τ ϕ ′ + ( 1 − τ ) ϕ 我们知道,DQN网络输出是长度为∣ A ∣ |\mathcal{A}| ∣ A ∣ Q ( s , a ) Q(s, a) Q ( s , a ) ∣ A ∣ = ∞ |\mathcal{A}|=\infty ∣ A ∣ = ∞ Deterministic policy gradient 有阐述,有兴趣可以自行了解,所谓的deterministic policy是相对于stochastic policy而言,其论证过程参考了Policy gradient for RL with function approximator ,二者的根本区别在于:
In the stochastic case, the policy gradient integrates over both state and action spaces, whereas in the deterministic case it only integrates over the state space.
以数学形式表达这句话,deterministic policy的objective是
J ( ϕ ) = ∫ S ρ μ ( s ) Q ( s , μ ϕ ( s ) ) d s J(\phi) = \int_{\mathcal{S}}\rho^\mu(s)Q(s, \mu_\phi(s))ds J ( ϕ ) = ∫ S ρ μ ( s ) Q ( s , μ ϕ ( s )) d s 而stochastic policy的objective是
J ( ϕ ) = ∫ S ρ μ ( s ) ∫ A μ ϕ ( s , a ) Q ( s , a ) d a d s J(\phi) = \int_{\mathcal{S}}\rho^\mu(s)\int_{\mathcal{A}}\mu_\phi(s, a) Q(s, a)dads J ( ϕ ) = ∫ S ρ μ ( s ) ∫ A μ ϕ ( s , a ) Q ( s , a ) d a d s 这里,deterministic policy μ ϕ ( s ) \mu_\phi(s) μ ϕ ( s ) μ ϕ ( s , a ) \mu_\phi(s, a) μ ϕ ( s , a )
我的理解,DDPG实际上是套用DQN和DPG的结合,Q network的更新很好理解,主要是理解DPG:
∇ ϕ J ( ϕ ) = E s ∼ ρ μ ( s ) [ ∇ ϕ Q θ ( s , μ ϕ ( s ) ) ] = ∫ S ρ μ ( s ) ∇ ϕ Q θ ( s , μ ϕ ( s ) ) d s = ∫ S ρ μ ( s ) ∇ a Q θ ( s , a ) ∣ a = μ ϕ ( s ) ∇ ϕ μ ϕ ( s ) d s \begin{aligned}\nabla_\phi J(\phi) &= \mathbb{E}_{s \sim \rho^\mu(s)}[\nabla_\phi Q_\theta(s,\mu_\phi(s))] \\&= \int_{\mathcal{S}}\rho^\mu(s) \nabla_\phi Q_\theta(s, \mu_\phi(s))ds \\&= \int_{\mathcal{S}}\rho^\mu(s) \nabla_aQ_\theta(s, a)|_{a=\mu_\phi(s)} \nabla_\phi \mu_\phi(s)ds\end{aligned} ∇ ϕ J ( ϕ ) = E s ∼ ρ μ ( s ) [ ∇ ϕ Q θ ( s , μ ϕ ( s ))] = ∫ S ρ μ ( s ) ∇ ϕ Q θ ( s , μ ϕ ( s )) d s = ∫ S ρ μ ( s ) ∇ a Q θ ( s , a ) ∣ a = μ ϕ ( s ) ∇ ϕ μ ϕ ( s ) d s 也就是说,我们调整policy network的参数ϕ \phi ϕ a = μ ϕ ( s ) a = \mu_\phi(s) a = μ ϕ ( s ) Q ( s , a ) Q(s, a) Q ( s , a )
TD3 是Double DQN的思路在DDPG上面的应用。我们前面提到,Double DQN主要解决的Q ( s , a ) Q(s,a) Q ( s , a )
我们在之前说过,policy gradient ∇ ϕ J ( ϕ ) \nabla_\phi J(\phi) ∇ ϕ J ( ϕ ) Q ( s , a ) Q(s, a) Q ( s , a ) Q ( s , μ ϕ ( s ) ) Q(s, \mu_\phi(s)) Q ( s , μ ϕ ( s )) E [ Q μ ( s , μ ϕ ( s ) ) ] ≤ E [ Q θ ( s , μ ϕ ( s ) ) ] \mathbb{E}[Q^\mu(s, \mu_\phi(s))] \le \mathbb{E}[Q_\theta(s, \mu_\phi(s))] E [ Q μ ( s , μ ϕ ( s ))] ≤ E [ Q θ ( s , μ ϕ ( s ))] Δ = ∇ ϕ J ( ϕ ) \Delta = \nabla_\phi J(\phi) Δ = ∇ ϕ J ( ϕ ) Δ → 0 \Delta \rightarrow 0 Δ → 0
E [ Q θ ( s , μ ϕ + Δ ( s ) ) ] ≥ E [ Q θ ( s , μ ϕ ( s ) ) ] ≈ E [ Q μ ϕ ( s , μ ϕ ( s ) ) ] E [ Q θ ( s , μ ϕ + Δ ( s ) ) ] ≥ E [ Q μ ϕ + Δ ( s , μ ϕ + Δ ( s ) ) ] \mathbb{E}[Q_\theta(s, \mu_{\phi+\Delta}(s))]\geq \mathbb{E}[Q_\theta(s, \mu_\phi(s))] \approx \mathbb{E}[Q^{\mu_\phi}(s, \mu_\phi(s))] \\\mathbb{E}[Q_\theta(s, \mu_{\phi+\Delta}(s))] \geq \mathbb{E}[Q^{\mu_{\phi+\Delta}}(s, \mu_{\phi+\Delta}(s))] E [ Q θ ( s , μ ϕ + Δ ( s ))] ≥ E [ Q θ ( s , μ ϕ ( s ))] ≈ E [ Q μ ϕ ( s , μ ϕ ( s ))] E [ Q θ ( s , μ ϕ + Δ ( s ))] ≥ E [ Q μ ϕ + Δ ( s , μ ϕ + Δ ( s ))] 为什么?因为当gradient足够小时,E [ Q θ ( s , μ ϕ + Δ ( s ) ) ] \mathbb{E}[Q_\theta(s, \mu_{\phi+\Delta}(s))] E [ Q θ ( s , μ ϕ + Δ ( s ))]
确立了以上观点,那么解决方案也很简单了,我们来看TD3 算法:
TD3 Algorithm:
Randomly initialise two Q network Q θ 1 ( s , a ) , Q θ 2 ( s , a ) Q_{\theta_1}(s, a), Q_{\theta_2}(s, a) Q θ 1 ( s , a ) , Q θ 2 ( s , a ) μ ϕ ( s ) \mu_\phi(s) μ ϕ ( s ) Q θ 1 ′ , Q θ 2 ′ , μ ϕ ′ Q_{\theta_1'}, Q_{\theta_2'},\mu_{\phi'} Q θ 1 ′ , Q θ 2 ′ , μ ϕ ′ R \mathcal{R} R σ \sigma σ For each episode:For each time-step t t t Sample an action a t ∼ N ( μ ϕ ( s t ) , σ 2 ) a_t \sim \mathcal{N}(\mu_\phi(s_t), \sigma^2) a t ∼ N ( μ ϕ ( s t ) , σ 2 ) s t + 1 s_{t+1} s t + 1 r t r_t r t d t d_t d t < s t , a t , r t , d t , s t + 1 > <s_t, a_t, r_t, d_t, s_{t+1}> < s t , a t , r t , d t , s t + 1 > R \mathcal{R} R
Sample a batch of N N N { s i , a i , r i , d i , s i ′ } \{s_i, a_i, r_i, d_i, s_i'\} { s i , a i , r i , d i , s i ′ }
target Q1 value q i , 1 = Q θ 1 ′ ( s i ′ , μ ϕ ′ ( s i ′ ) ) q_{i, 1} = Q_{\theta_1'}(s_i', \mu_{\phi'}(s_i')) q i , 1 = Q θ 1 ′ ( s i ′ , μ ϕ ′ ( s i ′ ))
target Q2 value q i , 2 = Q θ 2 ′ ( s i ′ , μ ϕ ′ ( s i ′ ) ) q_{i, 2} = Q_{\theta_2'}(s_i', \mu_{\phi'}(s_i')) q i , 2 = Q θ 2 ′ ( s i ′ , μ ϕ ′ ( s i ′ ))
target Q value q i = r i + γ ( 1 − d i ) min ( q i , 1 , q i , 2 ) q_i = r_i + \gamma (1 - d_i)\min(q_{i,1}, q_{i,2}) q i = r i + γ ( 1 − d i ) min ( q i , 1 , q i , 2 )
critic loss L ( θ 1 , θ 2 ) = N − 1 ∑ i ( ( Q θ 1 ( s i , a i ) − q i ) 2 + ( Q θ 2 ( s i , a i ) − q i ) 2 ) L(\theta_1, \theta_2)=N^{-1}\sum_i((Q_{\theta_1}(s_i, a_i)- q_i)^2 + (Q_{\theta_2}(s_i, a_i)- q_i)^2) L ( θ 1 , θ 2 ) = N − 1 ∑ i (( Q θ 1 ( s i , a i ) − q i ) 2 + ( Q θ 2 ( s i , a i ) − q i ) 2 )
policy gradient ∇ ϕ J ( ϕ ) = N − 1 ∑ i ∇ ϕ Q θ 1 ( s i , μ ϕ ( s i ) ) \nabla_\phi J(\phi) = N^{-1}\sum_i \nabla_\phi Q_{\theta_1}(s_i,\mu_\phi(s_i)) ∇ ϕ J ( ϕ ) = N − 1 ∑ i ∇ ϕ Q θ 1 ( s i , μ ϕ ( s i ))
update value networks:
θ 1 ← θ 1 − α ∇ θ 1 L ( θ 1 , θ 2 ) θ 2 ← θ 2 − α ∇ θ 2 L ( θ 1 , θ 2 ) \theta_1 \leftarrow \theta_1 - \alpha \nabla_{\theta_1}L(\theta_1, \theta_2) \\ \theta_2 \leftarrow \theta_2 - \alpha \nabla_{\theta_2}L(\theta_1, \theta_2) θ 1 ← θ 1 − α ∇ θ 1 L ( θ 1 , θ 2 ) θ 2 ← θ 2 − α ∇ θ 2 L ( θ 1 , θ 2 ) if t m o d T = 0 t \bmod T = 0 t mod T = 0
update policy network
ϕ ← ϕ + β ∇ ϕ J ( ϕ ) \phi \leftarrow \phi + \beta \nabla_\phi J(\phi ) ϕ ← ϕ + β ∇ ϕ J ( ϕ ) update target networks
θ 1 ′ ← τ θ 1 ′ + ( 1 − τ ) θ 1 θ 2 ′ ← τ θ 2 ′ + ( 1 − τ ) θ 2 ϕ ′ ← τ ϕ ′ + ( 1 − τ ) ϕ \theta_{1}' \leftarrow \tau\theta_{1}' + (1-\tau)\theta_1 \\ \theta_{2}' \leftarrow \tau\theta_{2}' + (1-\tau)\theta_2 \\ \phi' \leftarrow \tau\phi' + (1-\tau)\phi θ 1 ′ ← τ θ 1 ′ + ( 1 − τ ) θ 1 θ 2 ′ ← τ θ 2 ′ + ( 1 − τ ) θ 2 ϕ ′ ← τ ϕ ′ + ( 1 − τ ) ϕ 我们看到,作者用了两个Q network来estimate target Q value,且取用Q值较小的那一个,以此减轻Q值被高估的问题。另外,作者降低policy network被更新的频率,以此来与twin value network更新同步。
文章idea虽然简单易懂,但是作者花了大量篇幅论证over estimation error的存在,有兴趣的读者可以仔细阅读。
Soft Actor Critic 这篇文章的核心思路在于
J ( π θ ) = E τ ∼ p θ ( τ ) [ ∑ t ( r t + α H ( π θ ( s t ) ) ) ] J(\pi_\theta) = \mathbb{E}_{\tau \sim p_\theta(\tau)}[\sum_t(r_t + \alpha \mathcal{H}(\pi_\theta(s_t)))] J ( π θ ) = E τ ∼ p θ ( τ ) [ t ∑ ( r t + α H ( π θ ( s t )))] 我们重点理解stochastic policy及entropy这两个概念。
我们前面提到的DDPG和TD3,其policy network输出的是fixed value,此所谓deterministic policy。而SAC的policy输出的却是一个概率分布,具体来讲,其policy network输出的是一个multivariate Gaussian distribution的mean和log standard derivation。如此则
π θ ( a ∣ s t ) = N ( μ θ ( s t ) , σ θ ( s t ) ) \pi_\theta(a|s_t) = \mathcal{N}(\mu_\theta(s_t), \sigma_\theta(s_t)) π θ ( a ∣ s t ) = N ( μ θ ( s t ) , σ θ ( s t )) 我们设随机变量x x x f ( x ) f(x) f ( x )
H ( f ) = − ∫ f ( x ) log f ( x ) d x = − E x ∼ f ( x ) [ log f ( x ) ] \mathcal{H}(f) = - \int f(x) \log f(x) dx = -\mathbb{E}_{x\sim f(x)}[\log f(x)] H ( f ) = − ∫ f ( x ) log f ( x ) d x = − E x ∼ f ( x ) [ log f ( x )] 我们将其代入SAC的目标函数,则有
J ( π θ ) = E τ ∼ p θ ( τ ) [ R ( τ ) ] + α E τ ∼ p θ ( τ ) [ ∑ t H ( π θ ( s t ) ) ] = E τ ∼ p θ ( τ ) [ R ( τ ) ] − α E τ ∼ p θ ( τ ) [ ∑ t E a t ∼ π θ [ log π θ ( s t , a t ) ] ] = E τ ∼ p θ ( τ ) [ R ( τ ) ] − α E τ ∼ p θ ( τ ) [ ∑ t log π θ ( s t , a t ) ] \begin{aligned}J(\pi_\theta) &= \mathbb{E}_{\tau \sim p_\theta(\tau)}[R(\tau)]+ \alpha \mathbb{E}_{\tau \sim p_\theta(\tau)} [\sum_t\mathcal{H}(\pi_\theta(s_t))] \\ &= \mathbb{E}_{\tau \sim p_\theta(\tau)}[R(\tau)] - \alpha \mathbb{E}_{\tau \sim p_\theta(\tau)}[\sum_t \mathbb{E}_{a_t \sim \pi_\theta}[\log \pi_\theta(s_t, a_t)]] \\&= \mathbb{E}_{\tau \sim p_\theta(\tau)}[R(\tau)] - \alpha \mathbb{E}_{\tau \sim p_\theta(\tau)}[\sum_t \log \pi_\theta(s_t, a_t)] \\\end{aligned} J ( π θ ) = E τ ∼ p θ ( τ ) [ R ( τ )] + α E τ ∼ p θ ( τ ) [ t ∑ H ( π θ ( s t ))] = E τ ∼ p θ ( τ ) [ R ( τ )] − α E τ ∼ p θ ( τ ) [ t ∑ E a t ∼ π θ [ log π θ ( s t , a t )]] = E τ ∼ p θ ( τ ) [ R ( τ )] − α E τ ∼ p θ ( τ ) [ t ∑ log π θ ( s t , a t )] 要理解以上目标函数,就必须理解熵(entropy)的概念。
在热力学中,一个孤立系统熵衡量着其有序性:越混乱,平庸,低能态的系统,其熵越高;越有序,罕见,高能态的系统,其熵越低;所以熵的增加,代表着该系统从有序走向无序,从罕见走向平庸,从高能态走向低能态。热力学第二定律告诉我们,一个孤立系统的熵会自发增加,比如墨滴入水,火药爆炸,食物腐烂;熵增的过程,一般伴随着系统内部一些高能态物质释放能量转为低能态,从而使系统的平均温度得到提升。
熵这个概念被香农(Shannon Entropy)引到信息论中,则可以衡量一个分布的随机性。比如对于Bernoulli Distribution
P ( x ) = { p , x = 1 1 − p , x = 0 P(x) = \begin{cases}p, & x=1 \\1-p, & x = 0\end{cases} P ( x ) = { p , 1 − p , x = 1 x = 0 其熵
H ( P ) = − p log p − ( 1 − p ) log ( 1 − p ) \mathcal{H}(P) = - p\log p - (1-p)\log (1-p) H ( P ) = − p log p − ( 1 − p ) log ( 1 − p ) 在 p = 0.5 p = 0.5 p = 0.5 log 2 \log 2 log 2 p = 0 p=0 p = 0 p = 1 p=1 p = 1 0 0 0
再比如,对Gaussian Distribution
f ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{- \frac{(x - \mu)^2}{2\sigma^2}} f ( x ) = σ 2 π 1 e − 2 σ 2 ( x − μ ) 2 H ( f ) = − ∫ f ( x ) log f ( x ) d x = 1 + log ( 2 π σ 2 ) 2 \mathcal{H}(f) = - \int f(x) \log f(x) dx = \frac{1+ \log(2 \pi\sigma^2)}{2} H ( f ) = − ∫ f ( x ) log f ( x ) d x = 2 1 + log ( 2 π σ 2 ) 显然方差越大的分布,其熵越大。我们回到SAC算法中,刚刚提到,policy network的输出是multivariate Gaussian distribution N \mathcal{N} N
H ( N ) = ∑ k 1 + log ( 2 π σ k 2 ) 2 \mathcal{H}(\mathcal{N}) = \sum_k \frac{1+\log(2\pi\sigma_k^2)}{2} H ( N ) = k ∑ 2 1 + log ( 2 π σ k 2 ) 我们看到SAC的目标函数的第一项与原始RL相同,而其第二项则是policy的entropy的期望值。所以SAC的目标函数想要表达的意思是,我们的policy要拿到更高的exptected total return的同时,其分布的方差也要更大才好。
更大方差的policy,代表着对噪音的robustness,代表着action可以更随机一点,代表着exploration可以更多一点。从RL的角度讲,这样的policy确实更好。
同理,我们有
Q ^ π ( s , a ) = r ( s , a ) + E a ′ ∼ π , s ′ ∼ P [ Q π ( s ′ , a ′ ) + α H ( π ( s ′ ) ) ] = r ( s , a ) + E a ′ ∼ π , s ′ ∼ P [ Q π ( s ′ , a ′ ) − α E a ′ ∼ π [ log π ( s ′ , a ′ ) ] ] = r ( s , a ) + E a ′ ∼ π , s ′ ∼ P [ Q π ( s ′ , a ′ ) − α log π ( s ′ , a ′ ) ] \begin{aligned}\hat{Q}^\pi(s, a) &= r(s, a) + \mathbb{E}_{a'\sim\pi, s' \sim P}[Q^\pi(s', a') + \alpha \mathcal{H}(\pi(s'))] \\&=r(s, a) + \mathbb{E}_{a'\sim \pi, s'\sim P}[Q^\pi(s', a') - \alpha\mathbb{E}_{a' \sim \pi}[\log \pi(s', a')]] \\&= r(s, a) + \mathbb{E}_{a'\sim \pi, s' \sim P}[Q^\pi(s', a') - \alpha \log \pi(s', a')]\end{aligned} Q ^ π ( s , a ) = r ( s , a ) + E a ′ ∼ π , s ′ ∼ P [ Q π ( s ′ , a ′ ) + α H ( π ( s ′ ))] = r ( s , a ) + E a ′ ∼ π , s ′ ∼ P [ Q π ( s ′ , a ′ ) − α E a ′ ∼ π [ log π ( s ′ , a ′ )]] = r ( s , a ) + E a ′ ∼ π , s ′ ∼ P [ Q π ( s ′ , a ′ ) − α log π ( s ′ , a ′ )] V π ( s ) = E a ∼ π [ Q π ( s , a ) + α H ( π ( s ) ) ] = E a ∼ π [ Q π ( s , a ) − α E a ∼ π [ log π ( s , a ) ] ] = E a ∼ π [ Q π ( s , a ) − α log π ( s , a ) ] \begin{aligned}V^\pi(s) &= \mathbb{E}_{a \sim \pi}[Q^\pi(s, a) + \alpha \mathcal{H}(\pi(s))] \\&= \mathbb{E}_{a\sim\pi}[Q^\pi(s, a) - \alpha \mathbb{E}_{a \sim \pi}[\log \pi(s, a)]] \\&= \mathbb{E}_{a\sim\pi}[Q^\pi(s, a) - \alpha \log \pi(s, a)]\end{aligned} V π ( s ) = E a ∼ π [ Q π ( s , a ) + α H ( π ( s ))] = E a ∼ π [ Q π ( s , a ) − α E a ∼ π [ log π ( s , a )]] = E a ∼ π [ Q π ( s , a ) − α log π ( s , a )] 结合我们之前介绍的TD3算法,我们给出以下SAC 算法:
SAC Algorithm:
Randomly initialise two Q network Q θ 1 ( s , a ) , Q θ 2 ( s , a ) Q_{\theta_1}(s, a), Q_{\theta_2}(s, a) Q θ 1 ( s , a ) , Q θ 2 ( s , a ) π ϕ ( s ) = N ( μ ϕ ( s ) , σ ϕ ( s ) ) \pi_\phi(s) =\mathcal{N}(\mu_\phi(s), \sigma_\phi(s)) π ϕ ( s ) = N ( μ ϕ ( s ) , σ ϕ ( s )) Q θ 1 ′ , Q θ 2 ′ Q_{\theta_1'}, Q_{\theta_2'} Q θ 1 ′ , Q θ 2 ′ R \mathcal{R} R α = 1 \alpha = 1 α = 1 H ^ \hat{H} H ^ For each episode:For each timestep t t t Sample an action a t ∼ π ϕ ( s t ) a_t \sim \pi_\phi(s_t) a t ∼ π ϕ ( s t ) s t + 1 s_{t+1} s t + 1 r t r_t r t d t d_t d t < s t , a t , r t , d t , s t + 1 > <s_t, a_t, r_t, d_t, s_{t+1}> < s t , a t , r t , d t , s t + 1 > R \mathcal{R} R
Sample a batch of N N N { s i , a i , r i , d i , s i ′ } \{s_i, a_i, r_i, d_i, s_i'\} { s i , a i , r i , d i , s i ′ }
target actions a i ′ ∼ π ϕ ( s i ′ ) a_i' \sim \pi_\phi(s_i') a i ′ ∼ π ϕ ( s i ′ )
target Q1 value q ^ i , 1 = Q θ 1 ′ ( s i ′ , a i ′ ) \hat{q}_{i, 1} = Q{\theta_1'}(s_i', a_i') q ^ i , 1 = Q θ 1 ′ ( s i ′ , a i ′ )
target Q2 value q ^ i , 2 = Q θ 2 ′ ( s i ′ , a i ′ ) \hat{q}_{i, 2} = Q{\theta_2'}(s_i', a_i') q ^ i , 2 = Q θ 2 ′ ( s i ′ , a i ′ )
target Q value q ^ i = r i + γ ( 1 − d i ) ( min ( q ^ i , 1 , q ^ i , 2 ) − α log π ϕ ( s i ′ , a i ′ ) ) \hat{q}_i = r_i + \gamma (1 - d_i)(\min(\hat{q}_{i,1}, \hat{q}_{i,2})- \alpha \log \pi\phi(s_i', a_i')) q ^ i = r i + γ ( 1 − d i ) ( min ( q ^ i , 1 , q ^ i , 2 ) − α log π ϕ ( s i ′ , a i ′ ))
critic loss L ( θ 1 , θ 2 ) = N − 1 ∑ i ( ( Q θ 1 ( s i , a i ) − q ^ i ) 2 + ( Q θ 2 ( s i , a i ) − q ^ i ) 2 ) L(\theta_1, \theta_2)=N^{-1}\sum_i((Q_{\theta_1}(s_i, a_i)- \hat{q}_i)^2 + (Q_{\theta_2}(s_i, a_i)- \hat{q}_i)^2) L ( θ 1 , θ 2 ) = N − 1 ∑ i (( Q θ 1 ( s i , a i ) − q ^ i ) 2 + ( Q θ 2 ( s i , a i ) − q ^ i ) 2 )
current resampled actions a ^ i ∼ π ϕ ( s i ) \hat{a}_i \sim \pi\phi(s_i) a ^ i ∼ π ϕ ( s i )
current Q1 value q i , 1 = Q θ 1 ( s i , a ^ i ) q_{i, 1} = Q_{\theta_1}(s_i, \hat{a}_i) q i , 1 = Q θ 1 ( s i , a ^ i )
current Q2 value q i , 2 = Q θ 2 ( s i , a ^ i ) q_{i, 2} = Q_{\theta_2}(s_i, \hat{a}_i) q i , 2 = Q θ 2 ( s i , a ^ i )
policy gradient ∇ ϕ J ( ϕ ) = N − 1 ∑ i ∇ ϕ ( min ( q i , 1 , q i , 2 ) − α log π ϕ ( s i , a ^ i ) ) \nabla_\phi J(\phi) = N^{-1}\sum_i \nabla_\phi (\min(q_{i, 1}, q_{i, 2})-\alpha \log \pi_\phi(s_i, \hat{a}_i)) ∇ ϕ J ( ϕ ) = N − 1 ∑ i ∇ ϕ ( min ( q i , 1 , q i , 2 ) − α log π ϕ ( s i , a ^ i ))
temperature gradient Δ α = H ^ + N − 1 ∑ i log π ( s i , a i ) \Delta_\alpha = \hat{H} + N^{-1}\sum_i \log \pi(s_i, a_i) Δ α = H ^ + N − 1 ∑ i log π ( s i , a i )
update value networks
θ 1 ← θ 1 − η ∇ θ 1 L ( θ 1 , θ 2 ) θ 2 ← θ 2 − η ∇ θ 2 L ( θ 1 , θ 2 ) \theta_1 \leftarrow \theta_1 - \eta \nabla_{\theta_1}L(\theta_1, \theta_2) \\ \theta_2 \leftarrow \theta_2 - \eta \nabla_{\theta_2}L(\theta_1, \theta_2) θ 1 ← θ 1 − η ∇ θ 1 L ( θ 1 , θ 2 ) θ 2 ← θ 2 − η ∇ θ 2 L ( θ 1 , θ 2 ) update policy network ϕ ← ϕ + β ∇ ϕ J ( ϕ ) \phi \leftarrow \phi + \beta \nabla_\phi J(\phi ) ϕ ← ϕ + β ∇ ϕ J ( ϕ )
update temperature α ← α + β Δ α \alpha \leftarrow \alpha + \beta \Delta_\alpha α ← α + β Δ α
update target networks
θ 1 ′ ← τ θ 1 ′ + ( 1 − τ ) θ 1 θ 2 ′ ← τ θ 2 ′ + ( 1 − τ ) θ 2 \theta_{1}' \leftarrow \tau\theta_{1}' + (1-\tau)\theta_1 \\ \theta_{2}' \leftarrow \tau\theta_{2}' + (1-\tau)\theta_2 \\ θ 1 ′ ← τ θ 1 ′ + ( 1 − τ ) θ 1 θ 2 ′ ← τ θ 2 ′ + ( 1 − τ ) θ 2 关于SAC的收敛性,其前作SQL 中有更详细的论述,其实SAC与SQL的差别非常小,以至于SAC在ICLR被review时差点因为创新性不足被据掉,有兴趣的同学可以仔细拜读。
PPO 是online reinforcement learning的集大成(tricks)之作,该算法甚至被用来训练Dota2 AI 。我们在第一篇 的policy optimisation提到,加了importance sampling修正过后的Policy Gradient是
∇ θ η ( π θ ) = E τ ∼ p θ ′ ( τ ) [ π θ ( s t , a t ) π θ ′ ( s t , a t ) ∇ θ log π θ ( s t , a t ) A ( s t , a t ) ] ≈ 1 N ∑ i = 1 N π θ ( s t , i , a t , i ) π θ ′ ( s t , i , a t , i ) ∇ θ log π θ ( s t , i , a t , i ) A ( s t , i , a t , i ) \begin{aligned}\nabla_\theta\eta(\pi_\theta) &= \mathbb{E}_{\tau\sim p_{\theta'}(\tau)} [\frac{\pi_\theta(s_t, a_t)}{\pi_{\theta'}(s_t,a_t)}\nabla_\theta \log\pi_\theta(s_t, a_t)A(s_t, a_t)] \\&\approx \frac{1}{N}\sum_{i=1}^N \frac{\pi_\theta(s_{t,i}, a_{t,i})}{\pi_{\theta'}(s_{t,i},a_{t,i})}\nabla_\theta \log\pi_\theta(s_{t,i}, a_{t,i})A(s_{t,i}, a_{t,i})\end{aligned} ∇ θ η ( π θ ) = E τ ∼ p θ ′ ( τ ) [ π θ ′ ( s t , a t ) π θ ( s t , a t ) ∇ θ log π θ ( s t , a t ) A ( s t , a t )] ≈ N 1 i = 1 ∑ N π θ ′ ( s t , i , a t , i ) π θ ( s t , i , a t , i ) ∇ θ log π θ ( s t , i , a t , i ) A ( s t , i , a t , i ) 我们接下来会看到advantage function也可以被修正,我们称修正后的advantage function为Generalized Advantage Estimation 。
我们设TD error δ t + k = r ( s t + k , a t + k ) + γ V ( s t + k + 1 ) − V ( s t + k ) \delta_{t+k} = r(s_{t+k}, a_{t+k}) + \gamma V(s_{t+k+1}) - V(s_{t+k}) δ t + k = r ( s t + k , a t + k ) + γV ( s t + k + 1 ) − V ( s t + k )
A ( 0 ) ( s t , a t ) = Q ( s t , a t ) − V ( s t ) A ( 1 ) ( s t , a t ) = r ( s t , a t ) + γ V ( s t + 1 ) − V ( s t ) = δ t A ( 2 ) ( s t , a t ) = r ( s t , a t ) + γ r ( s t + 1 , a t + 1 ) + γ 2 V ( s t + 2 ) − V ( s t ) = δ t + γ δ t + 1 A ( 3 ) ( s t , a t ) = r ( s t , a t ) + γ r ( s t + 1 , a t + 1 ) + γ 2 r ( s t + 2 , a t + 2 ) + γ 3 V ( s t + 3 ) − V ( s t ) = δ t + γ δ t + 1 + γ 2 δ t + 2 … A ( ∞ ) ( s t , a t ) = ∑ k = 0 ∞ γ k r ( s t + k , a t + k ) − V ( s t ) = ∑ k = 0 ∞ γ k δ t + k \begin{aligned}A^{(0)}(s_t, a_t) &= Q(s_t, a_t) - V(s_t) \\A^{(1)}(s_t, a_t) &= r(s_t, a_t) + \gamma V(s_{t+1}) - V(s_t) &= \delta_t \\A^{(2)}(s_t, a_t) &= r(s_t, a_t) + \gamma r(s_{t+1}, a_{t+1}) + \gamma^2 V(s_{t+2}) - V(s_t) &= \delta_t + \gamma \delta_{t+1} \\A^{(3)}(s_t, a_t)&= r(s_t, a_t) + \gamma r(s_{t+1}, a_{t+1}) + \gamma^2 r(s_{t+2}, a_{t+2}) + \gamma^3 V(s_{t+3}) - V(s_t) &= \delta_t + \gamma\delta_{t+1} + \gamma^2\delta_{t+2} \\&\dots \\A^{(\infty)}(s_t, a_t) &= \sum_{k=0}^{\infty} \gamma^kr(s_{t+k}, a_{t+k}) - V(s_t) &= \sum_{k=0}^{\infty}\gamma^k\delta_{t+k}\end{aligned} A ( 0 ) ( s t , a t ) A ( 1 ) ( s t , a t ) A ( 2 ) ( s t , a t ) A ( 3 ) ( s t , a t ) A ( ∞ ) ( s t , a t ) = Q ( s t , a t ) − V ( s t ) = r ( s t , a t ) + γV ( s t + 1 ) − V ( s t ) = r ( s t , a t ) + γ r ( s t + 1 , a t + 1 ) + γ 2 V ( s t + 2 ) − V ( s t ) = r ( s t , a t ) + γ r ( s t + 1 , a t + 1 ) + γ 2 r ( s t + 2 , a t + 2 ) + γ 3 V ( s t + 3 ) − V ( s t ) … = k = 0 ∑ ∞ γ k r ( s t + k , a t + k ) − V ( s t ) = δ t = δ t + γ δ t + 1 = δ t + γ δ t + 1 + γ 2 δ t + 2 = k = 0 ∑ ∞ γ k δ t + k 一般我们会用NN做function estimator,所以如果用A ( 0 ) A^{(0)} A ( 0 ) A ( ∞ ) A^{(\infty)} A ( ∞ ) Q ( s t , a t ) Q(s_t,a_t) Q ( s t , a t ) r ( s t + k , a t + k ) r(s_{t+k}, a_{t+k}) r ( s t + k , a t + k )
GAE 提出
A ^ ( s t , a t ) = ( 1 − λ ) ( δ t ( 1 + λ + λ 2 + … ) + γ λ δ t + 1 ( 1 + λ + λ 2 + … ) + γ 2 λ 2 δ t + 2 ( 1 + λ + λ 2 + … ) … \begin{aligned}\hat{A}(s_t, a_t) = (1-\lambda)&(\delta_t(1 + \lambda + \lambda^2 + \dots) \\&+\gamma\lambda \delta_{t+1}(1+\lambda+\lambda^2 + \dots) \\&+\gamma^2\lambda^2\delta_{t+2}(1+\lambda+\lambda^2 + \dots) \\&\dots\end{aligned} A ^ ( s t , a t ) = ( 1 − λ ) ( δ t ( 1 + λ + λ 2 + … ) + γλ δ t + 1 ( 1 + λ + λ 2 + … ) + γ 2 λ 2 δ t + 2 ( 1 + λ + λ 2 + … ) … A ^ ( s t , a t ) = δ t + γ λ δ t + 1 + ( γ λ ) 2 δ t + 2 + … = ∑ k = 0 ∞ ( γ λ ) k δ t + k \begin{aligned}\hat{A}(s_t, a_t) &= \delta_t + \gamma\lambda\delta_{t+1} + (\gamma\lambda)^2\delta_{t+2} + \dots \\&= \sum_{k=0}^{\infty}(\gamma\lambda)^k\delta_{t+k}\end{aligned} A ^ ( s t , a t ) = δ t + γλ δ t + 1 + ( γλ ) 2 δ t + 2 + … = k = 0 ∑ ∞ ( γλ ) k δ t + k 显然,当λ = 0 \lambda = 0 λ = 0 A ^ ( s t , a t ) = A ( 1 ) ( s t , a t ) \hat{A}(s_t, a_t) = A^{(1)}(s_t, a_t) A ^ ( s t , a t ) = A ( 1 ) ( s t , a t ) λ = 1 \lambda = 1 λ = 1 A ^ ( s t , a t ) = A ( ∞ ) ( s t , a t ) \hat{A}(s_t, a_t)=A^{(\infty)}(s_t, a_t) A ^ ( s t , a t ) = A ( ∞ ) ( s t , a t ) λ \lambda λ
在PPO 中,作者将importance sampling和GAE结合,给出以下目标函数:
η ( θ ) = E τ ∼ p θ ′ ( τ ) [ π θ ( s t , a t ) π θ ′ ( s t , a t ) A ^ ( s t , a t ) ] \eta(\theta)=\mathbb{E}_{\tau \sim p_{\theta'}(\tau)}[\frac{\pi_\theta(s_t, a_t)}{\pi_{\theta'}(s_t, a_t)}\hat{A}(s_t, a_t)] η ( θ ) = E τ ∼ p θ ′ ( τ ) [ π θ ′ ( s t , a t ) π θ ( s t , a t ) A ^ ( s t , a t )] 在实践中,因为r = π θ ( s t , a t ) / π θ ′ ( s t , a t ) r = \pi_\theta(s_t, a_t)/\pi_{\theta'}(s_t, a_t) r = π θ ( s t , a t ) / π θ ′ ( s t , a t )
L ( r , A ^ ) = { ( 1 + ϵ ) A ^ , A ^ ≥ 0 , r ≥ 1 + ϵ r A ^ , A ^ ≥ 0 , 0 ≤ r < 1 + ϵ ( 1 − ϵ ) A ^ , A ^ < 0 , 0 ≤ r < 1 − ϵ r A ^ , A ^ < 0 , r > 1 − ϵ L(r, \hat{A}) = \begin{cases}(1+\epsilon)\hat{A}, \quad \hat{A} \geq 0, r \geq 1+ \epsilon \\r\hat{A}, \qquad \hat{A} \geq 0, 0 \leq r < 1+\epsilon \\(1 - \epsilon)\hat{A}, \quad \hat{A} < 0, 0 \leq r < 1 - \epsilon \\r\hat{A}, \qquad \hat{A}<0, r > 1 - \epsilon \end{cases} L ( r , A ^ ) = ⎩ ⎨ ⎧ ( 1 + ϵ ) A ^ , A ^ ≥ 0 , r ≥ 1 + ϵ r A ^ , A ^ ≥ 0 , 0 ≤ r < 1 + ϵ ( 1 − ϵ ) A ^ , A ^ < 0 , 0 ≤ r < 1 − ϵ r A ^ , A ^ < 0 , r > 1 − ϵ 亦或者
L ( r , A ^ ) = min ( r A ^ , clip ( r , 1 − ϵ , 1 + ϵ ) A ^ ) L(r, \hat{A}) = \min(r\hat{A}, \text{clip}(r, 1-\epsilon, 1+\epsilon)\hat{A}) L ( r , A ^ ) = min ( r A ^ , clip ( r , 1 − ϵ , 1 + ϵ ) A ^ ) 这么简单的idea,自然难登大雅之堂,作者又是如何把结果包装的那么好看,让大家接受的呢?
当然是用trick!在code中用,在paper中不提。然而这么火的算法,必然会被人锤。在这篇 文章中,作者比较了PPO的code中使用的各种trick对实验结果的影响,结果却十分呵呵哒:相比于其他trick,PPO的ratio clip对结果的影响却是微乎其微的。
这种现象在DL界的文章中非常普遍,也十分遭人厌恶,甚至有劣币驱逐良币的趋势,非常令人失望。