关于深度学习,网上的教程很多,很多也写的比我好,这里仅从自己的角度,简单谈谈对深度学习的理解。
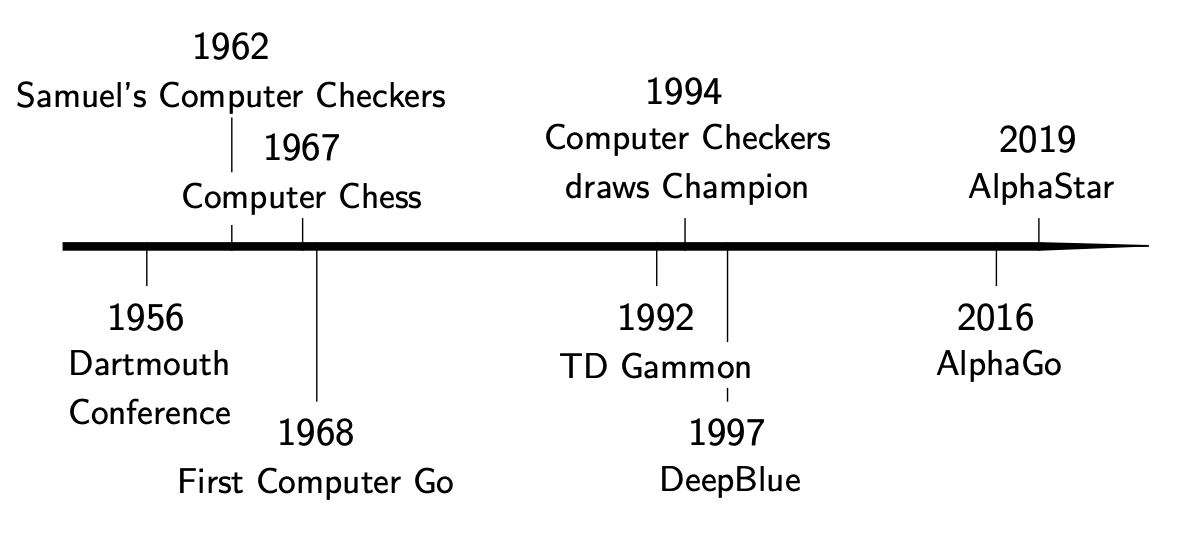
人工智能的历史,可能和数字计算机的历史一样长。早期人们设计AI程序,更多的是为了测试和展示计算机和算法,吸引公众注意;在应用领域,其实一直很狭窄,比如1950年香农设计的机械鼠Theusus ,能够解决简单的迷宫问题。1956年的达特矛斯会议 ,堪比AI届的索尔维会议,现代AI的很多概念和框架,在那场会议中都有提及和确立。这之后,随着计算机算力的提升和算法的进步,AI在各种智力游戏竞赛中逐个击败人类;而这些历史事件,往往会引爆公众的讨论和焦虑,也伴随着资本的潮起潮落。
如果你将这些历史事件放在时间轴上看的话,很容易发现AI的三次浪潮所对应的时间分段;这其中,以本次AI浪潮最为汹涌,对人类社会的影响,我认为也最为深远。
人工智能下的各种理论,流派,分支,非常繁多;再加上媒体的渲染,很多时候连从业者都很难说清楚其中的边界;仅讨论当下最常见的三个术语之间的关系,可能会是这样:
Deep Learning ⊂ Machine Learning ⊂ Artificial Intelligence \text{Deep Learning} \sub \text{Machine Learning} \sub \text{Artificial Intelligence} Deep Learning ⊂ Machine Learning ⊂ Artificial Intelligence 要理解深度学习的基础,拿这分类,回归和拟合三个问题来做讨论恐怕最合适不过了,因为深度学习的诸多课题,其实都能在这三个问题中找到雏形。
Given data points X = { x i ∣ i = 1 , 2 , … , K ; x i ∈ R N } X =\{x_i |i = 1,2, \dots, K; x_i \in \mathbb{R}^N \} X = { x i ∣ i = 1 , 2 , … , K ; x i ∈ R N } Y = { y i ∣ i = 1 , 2 , … , M ; y i ∈ R N } Y=\{y_i| i = 1, 2, \dots, M; y_i \in \mathbb{R}^N\} Y = { y i ∣ i = 1 , 2 , … , M ; y i ∈ R N } f w f_w f w
f w ( x ) > 0 , ∀ x ∈ X f w ( y ) < 0 , ∀ y ∈ Y f_w(x) > 0, \forall x \in X \\ f_w(y) < 0, \forall y \in Y f w ( x ) > 0 , ∀ x ∈ X f w ( y ) < 0 , ∀ y ∈ Y 从几何角度理解:
寻找一个N N N X X X Y Y Y
假设f w f_w f w
f w ( z ) = w o + w 1 T z + 1 2 z T w 2 z w o ∈ R , w 1 ∈ R N , w 2 ∈ R N × N f_w(z) = w_o + w_1^Tz + \frac{1}{2} z^Tw_2z \\w_o \in \mathbb{R}, w_1 \in \mathbb{R}^N, w_2 \in \mathbb{R}^{N\times N} f w ( z ) = w o + w 1 T z + 2 1 z T w 2 z w o ∈ R , w 1 ∈ R N , w 2 ∈ R N × N 将X , Y X,Y X , Y
w 0 + w 1 T X + 1 2 X T w 2 X > 0 w 0 + w 1 T Y + 1 2 Y T w 2 Y < 0 w_0 + w_1^T X + \frac{1}{2}X^Tw_2 X > 0 \\w_0 + w_1^T Y + \frac{1}{2}Y^Tw_2 Y < 0 w 0 + w 1 T X + 2 1 X T w 2 X > 0 w 0 + w 1 T Y + 2 1 Y T w 2 Y < 0 P = M + K P = M + K P = M + K Q = 1 + N + N 2 Q = 1+N+N^2 Q = 1 + N + N 2
min w 0 subject to A w > 0 where A ∈ R P × Q is known \begin{aligned}\min_{w} \quad & 0 \\\text{subject to} \quad & Aw > 0 \\\text{where} \quad & A \in \mathbb{R}^{P\times Q} \quad \text{is known}\end{aligned} w min subject to where 0 A w > 0 A ∈ R P × Q is known 这就是一个简单的凸优化问题了。当P > Q P > Q P > Q f w f_w f w
Given X = { x i ∣ i = 1 , 2 , … , K ; x i ∈ R N } X =\{x_i |i = 1,2, \dots, K; x_i \in \mathbb{R}^N \} X = { x i ∣ i = 1 , 2 , … , K ; x i ∈ R N } f w f_w f w ∥ f w ( X ) ∥ \|f_w(X)\| ∥ f w ( X ) ∥
从几何角度理解:
寻找一个N N N X X X
我们同样假设f w f_w f w X X X
min w w T A T A w where A ∈ R K × Q is known \begin{aligned}\min_{w} \quad & w^TA^TAw \\\text{where} \quad & A \in \mathbb{R}^{K\times Q} \quad \text{is known}\end{aligned} w min where w T A T A w A ∈ R K × Q is known 我们发现,无论是分类,还是回归,其实都是在做拟合: 分类问题其实在拟合数据边界,回归问题其实在拟合数据分布。很多情况下,也可以将其转化为简单的凸优化问题。但是,我们之前的模型很显然存在一个很大的问题:当数据在空间中的分布不符合我们的预期,即
对分类问题,{ w ∣ A w > 0 } = ∅ \{w|Aw > 0\} = \empty { w ∣ A w > 0 } = ∅ 对回归问题,∥ ∣ f w ( X ) ∥ \||f_w(X)\| ∥∣ f w ( X ) ∥ 我们当然可以通过增加f w f_w f w w w w Q = 1 + N + N 2 + … Q = 1 + N + N^2 + \dots Q = 1 + N + N 2 + … N N N f w f_w f w
我们看到,当polynomial的order M M M M M M ∥ f w ( X ) ∥ = 0 \|f_w(X)\|=0 ∥ f w ( X ) ∥ = 0
我们在上一节假设f w f_w f w f w f_w f w
f w ( z ) = w 0 + w 1 T z w o ∈ R , w 1 ∈ R N f_w(z) = w_0 + w_1^Tz \\w_o \in \mathbb{R}, w_1 \in \mathbb{R}^N f w ( z ) = w 0 + w 1 T z w o ∈ R , w 1 ∈ R N 很显然,这样的f w f_w f w
如果简单的进行函数嵌套,比如
f W ( z ) = f 3 ( f 2 ( f 1 ( z ) ) ) , z ∈ R N f 1 ( z ) = W 1 z + b 1 , W 1 ∈ R M × N , b 1 ∈ R M , z ∈ R N f 2 ( z ) = W 2 z + b 2 , W 2 ∈ R K × M , b 2 ∈ R K , z ∈ R M f 3 ( z ) = W 3 z + b 3 , W 3 ∈ R 1 × K , b 3 ∈ R , z ∈ R K \begin{aligned}f_W(z) &= f_{3}(f_{2}(f_{1}(z))), \quad z \in \mathbb{R}^{N} \\f_1(z) &= W_1z + b_1, \quad W_1 \in \mathbb{R}^{M \times N}, b_1 \in \mathbb{R}^{M}, z \in \mathbb{R}^N \\f_2(z) &= W_2z + b_2, \quad W_2 \in \mathbb{R}^{K \times M}, b_2 \in \mathbb{R}^{K}, z \in \mathbb{R}^M \\f_3(z) &= W_3z + b_3, \quad W_3 \in \mathbb{R}^{1 \times K}, b_3 \in \mathbb{R}, z \in \mathbb{R}^K \\\end{aligned} f W ( z ) f 1 ( z ) f 2 ( z ) f 3 ( z ) = f 3 ( f 2 ( f 1 ( z ))) , z ∈ R N = W 1 z + b 1 , W 1 ∈ R M × N , b 1 ∈ R M , z ∈ R N = W 2 z + b 2 , W 2 ∈ R K × M , b 2 ∈ R K , z ∈ R M = W 3 z + b 3 , W 3 ∈ R 1 × K , b 3 ∈ R , z ∈ R K 那么
f W ( z ) = W 3 ( W 2 ( W 1 z + b 1 ) + b 2 ) + b 3 = W 3 W 2 W 1 z + b 3 + W 3 b 2 + W 3 W 2 b 1 = A z + b \begin{aligned}f_W(z) &= W_3(W_2(W_1z + b_1)+b_2)+b_3 \\&= W_3 W_2 W_1z + b_3 + W_3b_2 + W_3W_2b_1 \\&= Az + b\end{aligned} f W ( z ) = W 3 ( W 2 ( W 1 z + b 1 ) + b 2 ) + b 3 = W 3 W 2 W 1 z + b 3 + W 3 b 2 + W 3 W 2 b 1 = A z + b where A = W 3 W 2 W 1 ∈ R 1 × N , b = b 3 + W 3 b 2 + W 3 W 2 b 1 ∈ R \text{where} \quad A = W_3 W_2 W_1 \in \mathbb{R}^{1 \times N}, \quad b = b_3 + W_3b_2 + W_3W_2b_1 \in \mathbb{R} where A = W 3 W 2 W 1 ∈ R 1 × N , b = b 3 + W 3 b 2 + W 3 W 2 b 1 ∈ R 显然,嵌套后的复合函数依旧是个超平面,并没有什么效果。但是,如果给每个函数增加非线性性,那么结果就不一样了。比如
f W ( z ) = f 3 ( f 2 ( f 1 ( z ) ) ) , z ∈ R N f 1 ( z ) = σ ( W 1 z + b 1 ) , W 1 ∈ R M × N , b 1 ∈ R M , z ∈ R N f 2 ( z ) = σ ( W 2 z + b 2 ) , W 2 ∈ R K × M , b 2 ∈ R K , z ∈ R M f 3 ( z ) = σ ( W 3 z + b 3 ) , W 3 ∈ R 1 × K , b 3 ∈ R , z ∈ R K \begin{aligned}f_W(z) &= f_{3}(f_{2}(f_{1}(z))), \quad z \in \mathbb{R}^{N} \\f_1(z) &= \sigma(W_1z + b_1), \quad W_1 \in \mathbb{R}^{M \times N}, b_1 \in \mathbb{R}^{M}, z \in \mathbb{R}^N \\f_2(z) &= \sigma(W_2z + b_2), \quad W_2 \in \mathbb{R}^{K \times M}, b_2 \in \mathbb{R}^{K}, z \in \mathbb{R}^M \\f_3(z) &= \sigma(W_3z + b_3), \quad W_3 \in \mathbb{R}^{1 \times K}, b_3 \in \mathbb{R}, z \in \mathbb{R}^K \\\end{aligned} f W ( z ) f 1 ( z ) f 2 ( z ) f 3 ( z ) = f 3 ( f 2 ( f 1 ( z ))) , z ∈ R N = σ ( W 1 z + b 1 ) , W 1 ∈ R M × N , b 1 ∈ R M , z ∈ R N = σ ( W 2 z + b 2 ) , W 2 ∈ R K × M , b 2 ∈ R K , z ∈ R M = σ ( W 3 z + b 3 ) , W 3 ∈ R 1 × K , b 3 ∈ R , z ∈ R K where σ ( x ) = { x , x ≥ 0 0 , x < 0 \text{where} \quad \sigma(x) = \begin{cases}x, x \geq 0\\0, x < 0\end{cases} where σ ( x ) = { x , x ≥ 0 0 , x < 0 这里我们选择的这个非线性函数σ ( x ) \sigma(x) σ ( x ) R e L U ReLU R e LU Activation Function 。
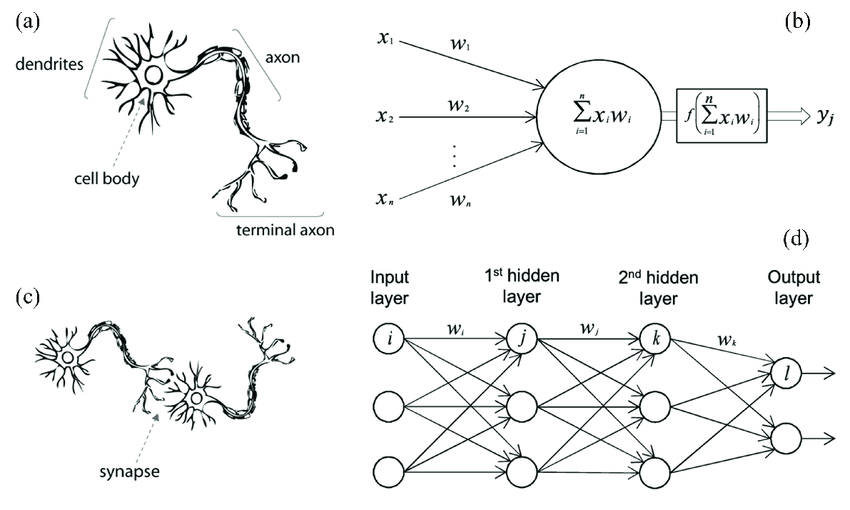
如果了解生物神经元的工作原理,就会发现其与我们上面介绍的感知机非常相似。生物神经元接受来自上一层神经元的刺激,在达到阈值时放电,将电信号通过轴突传导至下一层神经元,这其实就是f w ( x ) = σ ( A x + b ) f_w(x) = \sigma(Ax+b) f w ( x ) = σ ( A x + b ) x x x A A A b b b σ \sigma σ f w ( z ) f_w(z) f w ( z ) f W ( z ) f_W(z) f W ( z )
然而,即便是单个神经元,人工神经元的构造相比于生物神经元也显得太过粗糙,更何况生物神经元的种类和功能繁多,且神经元之间的通信机制不限于互相之间的神经连接。而生物神经网络,更是远比人工神经网络复杂和多变。先别说哺乳动物了,远比它低级的C. Elegans ,其300余个神经元的位置,功能,连接已全部搞清楚,而且已经能在计算机上进行完整的模拟 ,然而其整个神经网络的协作和宏观表现,以及与其他生物信号之间的通信,我们还不能说完全弄清;所以,如今的人工神经网络框架,依然有非常大的进步空间。
这一步其实非常简单,只需要初步的高数知识。我们以regression为例:
Given X ∈ R M × N X \in \mathbb{R}^{M\times N} X ∈ R M × N Y ∈ R N Y \in \mathbb{R}^N Y ∈ R N f W f_W f W ∥ Y − f W ( X ) ∥ \|Y - f_W(X)\| ∥ Y − f W ( X ) ∥
我们以L2 norm为例,
min W ∣ ∣ Y − f W ( X ) ∣ ∣ 2 2 \min_{W} ||Y - f_W(X)||_2^2 W min ∣∣ Y − f W ( X ) ∣ ∣ 2 2 设损失函数,
L ( W ) = 1 2 ( f W ( X ) − Y ) T ( f W ( X ) − Y ) \begin{aligned}L(W) = \frac{1}{2}(f_W(X)-Y)^T(f_W(X)-Y)\end{aligned} L ( W ) = 2 1 ( f W ( X ) − Y ) T ( f W ( X ) − Y ) 我们对L W L_W L W
L ( W + δ W ) ≈ L ( W ) + L ′ ( W ) δ W L(W+\delta W) \approx L(W) + L'(W)\delta W L ( W + δ W ) ≈ L ( W ) + L ′ ( W ) δ W 当δ W = − L ′ ( W ) T , α → 0 + \delta W = - L'(W)^T, \alpha \to 0^+ δ W = − L ′ ( W ) T , α → 0 +
L ( W + δ W ) = L ( W ) − α ∣ ∣ L ′ ( W ) ∣ ∣ 2 2 < L ( W ) L(W + \delta W) = L(W) - \alpha ||L'(W)||_2^2 < L(W) L ( W + δ W ) = L ( W ) − α ∣∣ L ′ ( W ) ∣ ∣ 2 2 < L ( W ) 也就是说,当W W W L ′ ( W ) L'(W) L ′ ( W ) L ( W ) L(W) L ( W )
完整的算法:
Random initialisation W ← W 0 W \gets W_0 W ← W 0 α \alpha α Calculate δ W = L ′ ( W n − 1 ) , W ← W n = W n − 1 − α δ W \delta W = L'(W_{n-1}), W \gets W_{n} = W_{n-1} - \alpha \delta W δ W = L ′ ( W n − 1 ) , W ← W n = W n − 1 − α δ W If ∣ L ( W n ) − L ( W n − 1 ) ∣ |L(W_{n}) - L(W_{n-1})| ∣ L ( W n ) − L ( W n − 1 ) ∣ W n W_n W n 所以问题的关键是求L ′ ( W ) L'(W) L ′ ( W )
f W ( X ) = ( f 3 ∘ f 2 ∘ f 1 ) ( X ) Y 1 = f 1 ( X ) = σ ( W 1 X + b 1 ) Y 2 = f 2 ( Y 1 ) = σ ( W 2 Y 1 + b 2 ) Y 3 = f 3 ( Y 2 ) = σ ( W 3 Y 2 + b 3 ) L ( W ) = ∣ ∣ Y 3 − Y ∣ ∣ 2 2 f_W(X) = (f_3 \circ f_2 \circ f_1)(X)\\Y_1 = f_1(X)= \sigma(W_1X+ b_1)\\Y_2 = f_2(Y_1) = \sigma(W_2Y_1 + b_2)\\Y_3 = f_3(Y_2) = \sigma(W_3Y_2 + b_3) \\L(W) = ||Y_3 - Y||_2^2 f W ( X ) = ( f 3 ∘ f 2 ∘ f 1 ) ( X ) Y 1 = f 1 ( X ) = σ ( W 1 X + b 1 ) Y 2 = f 2 ( Y 1 ) = σ ( W 2 Y 1 + b 2 ) Y 3 = f 3 ( Y 2 ) = σ ( W 3 Y 2 + b 3 ) L ( W ) = ∣∣ Y 3 − Y ∣ ∣ 2 2 那么
∂ L ∂ W 3 = ∂ L ∂ Y 3 ∂ Y 3 ∂ W 3 = ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × Y 2 ∂ L ∂ W 2 = ∂ L ∂ Y 3 ∂ Y 3 ∂ Y 2 ∂ Y 2 ∂ W 2 = ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × W 3 ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × Y 1 ∂ L ∂ W 1 = ∂ L ∂ Y 3 ∂ Y 3 ∂ Y 2 ∂ Y 2 ∂ Y 1 ∂ Y 1 ∂ W 1 = ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × W 3 ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × W 2 ⋅ σ ′ ( W 1 X + b 1 ) T × X \begin{aligned}\frac{\partial L}{\partial W_3} &= \frac{\partial L}{\partial Y_3}\frac{\partial Y_3}{\partial W_3} =(Y_3 - Y)^T \cdot \sigma'(W_3Y_2 + b_3)^T \times Y_2 \\ \frac{\partial L}{\partial W_2} &= \frac{\partial L}{\partial Y_3}\frac{\partial Y_3}{\partial Y_2}\frac{\partial Y_2}{\partial W_2} =(Y_3 - Y)^T \cdot \sigma'(W_3Y_2 + b_3)^T \times W_3 \cdot \sigma'(W_2Y_1 + b_2)^T \times Y_1 \\ \frac{\partial L}{\partial W_1} &= \frac{\partial L}{\partial Y_3}\frac{\partial Y_3}{\partial Y_2}\frac{\partial Y_2}{\partial Y_1}\frac{\partial Y_1}{\partial W_1} =(Y_3 - Y)^T \cdot \sigma'(W_3Y_2 + b_3)^T \times W_3 \cdot \sigma'(W_2Y_1 + b_2)^T \times W_2 \cdot \sigma'(W_1X+b_1)^T \times X\end{aligned} \\ ∂ W 3 ∂ L ∂ W 2 ∂ L ∂ W 1 ∂ L = ∂ Y 3 ∂ L ∂ W 3 ∂ Y 3 = ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × Y 2 = ∂ Y 3 ∂ L ∂ Y 2 ∂ Y 3 ∂ W 2 ∂ Y 2 = ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × W 3 ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × Y 1 = ∂ Y 3 ∂ L ∂ Y 2 ∂ Y 3 ∂ Y 1 ∂ Y 2 ∂ W 1 ∂ Y 1 = ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × W 3 ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × W 2 ⋅ σ ′ ( W 1 X + b 1 ) T × X L L L b 1 , b 2 , b 3 b_1, b_2, b_3 b 1 , b 2 , b 3 ⋅ \cdot ⋅ × \times ×
import numpy as np
import matplotlib. pyplot as plt
fn = {
'relu' : lambda x: np. where( x < 0 , 0 , x) ,
'l2' : lambda x, y: 0.5 * ( x - y) ** 2 ,
'none' : lambda x: x,
'ce' : lambda x: x
}
df = {
'relu' : lambda x: np. where( x < 0 , 0 , 1 ) ,
'none' : lambda x: 1 ,
'l2' : lambda x, y: x - y,
'ce' : lambda x: x
}
class LinearLayer :
def __init__ ( self, in_dim, out_dim, act_fn, lr= 0.1 ) :
self. W = np. random. randn( in_dim, out_dim) / in_dim
self. b = np. random. randn( out_dim)
self. dw = None
self. db = None
self. fn = fn[ act_fn]
self. df = df[ act_fn]
self. lr = lr
def forward ( self, x) :
self. x = x
self. h = np. dot( x, self. W) + self. b
return self. fn( self. h)
def backward ( self, g) :
self. dw = ( g * self. df( self. h) ) . transpose( ) @ self. x
self. db = ( g * self. df( self. h) ) . transpose( ) . sum ( - 1 )
return ( g * self. df( self. h) ) @ self. W. transpose( )
def update ( self, lr= None ) :
if lr is not None and self. dw is not None and self. db is not None :
self. W -= self. dw. transpose( ) * lr
self. b -= self. db * lr
self. dw = None
self. db = None
class MLP :
def __init__ ( self, dims= [ 1 , 5 , 5 , 1 ] , act= 'relu' , cost= 'l2' ) :
self. layers = [ ]
self. fn = fn[ cost]
self. df = df[ cost]
for i in range ( len ( dims) - 1 ) :
act = act if i < len ( dims) - 2 else 'none'
layer = LinearLayer( dims[ i] , dims[ i+ 1 ] , act)
self. layers. append( layer)
def forward ( self, x) :
for layer in self. layers:
x = layer. forward( x)
return x
def backward ( self, g) :
for layer in self. layers[ : : - 1 ] :
g = layer. backward( g)
def update ( self, lr) :
for layer in self. layers:
layer. update( lr)
def loss ( self, x, y) :
return self. fn( x, y) . mean( )
def loss_grad ( self, x, y) :
return self. df( x, y)
base_lr = 0.1
dims = [ 1 , 10 , 10 , 1 ]
N = 500
x = np. linspace( - 10 , 10 , N) . reshape( N, 1 )
y = np. sin( x) + np. random. randn( N) . reshape( N, 1 )
nn = MLP( dims)
lr = base_lr / N
losses = [ ]
for epoch in range ( 10000 ) :
y_ = nn. forward( x)
loss = nn. loss( y_, y)
losses. append( loss)
grad = nn. loss_grad( y_, y)
nn. backward( grad)
nn. update( lr)
plt. figure( )
plt. plot( x, y)
plt. plot( x, y_, 'r' )
plt. figure( )
plt. plot( losses[ : 100 ] )
plt. show( )
我们看到使用ReLU激活函数的MLP拟合的曲面是锯齿状的,这其实非常符合我们的预期:使用若干个linear region的组合来拟合目标曲面。
早在1989年,该定理就得到了证明:
For any f : R d → R D f:\mathbb{R}^d \to \mathbb{R}^D f : R d → R D f ϵ = W 2 ∘ σ ∘ W 1 : R d → R D f_\epsilon = W_2 \circ \sigma \circ W_1: \mathbb{R}^d \to \mathbb{R}^D f ϵ = W 2 ∘ σ ∘ W 1 : R d → R D W 1 , W 2 W_1, W_2 W 1 , W 2 σ \sigma σ
sup x ∣ ∣ f ( x ) − f ϵ ( x ) ∣ ∣ < ϵ \sup_{x} || f(x) - f_\epsilon(x) || < \epsilon x sup ∣∣ f ( x ) − f ϵ ( x ) ∣∣ < ϵ holds for artitary small ϵ \epsilon ϵ
它说明,我们用有一个隐藏层不限宽度的MLP,就足以逼近任何连续函数。
如果用MLP处理2D data,比如图像,一般做法是将2D data vectorize成1D,再交给MLP训练。显然这用做法丢弃了原有数据的空间信息(spatial information),卷积神经网络为此而生。
如下所示,⊛ \circledast ⊛ 4 × 4 4\times 4 4 × 4 3 × 3 3\times3 3 × 3 4 × 1 4 \times 1 4 × 1 2 × 2 2\times 2 2 × 2 Caffe 是通过im2col的函数如此操作的。由此可见,卷积本质上也是Linear Operation。
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ] ⊛ [ 1 2 3 4 5 6 7 8 9 ] = [ 1 2 3 5 6 7 9 10 11 2 3 4 6 7 8 10 11 12 5 6 7 9 10 11 13 14 15 6 7 8 10 11 12 14 15 16 ] × [ 1 2 3 4 5 6 7 8 9 ] = [ a b c d ] = [ a b c d ] \begin{bmatrix}1 & 2 & 3 & 4 \\5 & 6 & 7 & 8 \\9 & 10 & 11 & 12 \\13 & 14 & 15 & 16 \\\end{bmatrix} \circledast \begin{bmatrix}1 & 2 & 3 \\4 & 5 & 6 \\7 & 8 & 9 \\\end{bmatrix} = \begin{bmatrix}1 & 2 & 3 & 5 & 6 & 7 & 9 & 10 & 11 \\2 & 3 & 4 & 6 & 7 & 8 & 10 & 11 & 12 \\5 & 6 & 7 & 9 & 10 & 11 & 13 & 14 & 15 \\6 & 7 & 8 & 10 & 11 & 12 & 14 & 15 & 16\end{bmatrix} \times \begin{bmatrix}1 \\2 \\3 \\4 \\5 \\6 \\7 \\8 \\9 \end{bmatrix} = \begin{bmatrix}a \\b \\c \\d\end{bmatrix} = \begin{bmatrix}a & b \\c & d\end{bmatrix} 1 5 9 13 2 6 10 14 3 7 11 15 4 8 12 16 ⊛ 1 4 7 2 5 8 3 6 9 = 1 2 5 6 2 3 6 7 3 4 7 8 5 6 9 10 6 7 10 11 7 8 11 12 9 10 13 14 10 11 14 15 11 12 15 16 × 1 2 3 4 5 6 7 8 9 = a b c d = [ a c b d ] 在实践中,N N N N × H x × W x × C N \times H_x \times W_x \times C N × H x × W x × C H y × W y × C × D H_y \times W_y \times C \times D H y × W y × C × D N × H z × W z × D N \times H_z \times W_z \times D N × H z × W z × D H × W H \times W H × W C , D C,D C , D
早期的CNN在MNIST 数据集上取得了很不错的成绩。比如上面的LeNet,它用较少的参数量轻松超越了MLP的结果。这表明,人工神经网络有着很大的优化空间。我们在下一节会看到,深度学习的诸多变种都是围绕着卷积进行的。
本次深度学习的引爆,有两个关键因素:数据和算力。互联网时代的到来,为我们提供了海量的数据,特别是图片和视频数据。而这些数据的检索,对算法提出了新的要求。处理这些海量数据,又对计算机的算力提出很高的要求。而摩尔定律又在GPU上得到恰到好处的延续。至此,深度学习的爆发,似乎只是时间问题。
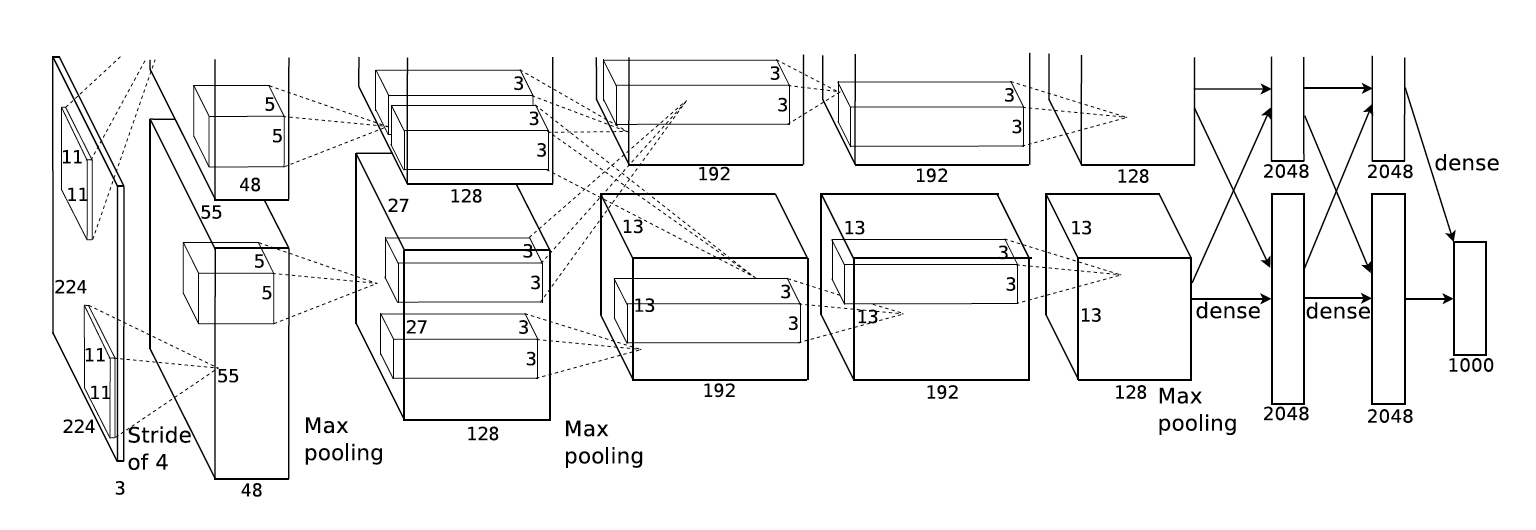
2012年,由Alex Krizhevsk提出的AlexNet 参加了当年的ImageNet 大规模视觉识别挑战赛,拿到第一名的夺目成绩,由此拉开了深度学习在视觉竞赛的序幕。以今天的眼光看来,AlexNet相较于LeNet并没有太多改进,无非是扩大了网络的规模。
但是,它开创了本领域很多第一:
第一次用CNN在如此大规模的数据集(1M images, 1000 classes)上取得远超传统算法的成绩。 第一次设计使用如此大规模的神经网络且成功完成训练。 第一次用GPU编程加速训练如此大规模的神经网络,使其训练时间在可接受范围内(5-6 days)。 在不久之后,有人便用了更大更深的网络(VGG ),在同样的数据集下取得了更好的成绩。
ResNet 人们随后发现,简单的增加网络的深度,并不能使结果变得更好,相反结果会变得更差。回看我们在BP中推导出的三层MLP的梯度公式:
∂ L ∂ W 1 = ∂ L ∂ Y 3 ∂ Y 3 ∂ Y 2 ∂ Y 2 ∂ Y 1 ∂ Y 1 ∂ W 1 = ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × W 3 ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × W 2 ⋅ σ ′ ( W 1 X + b 1 ) T × X \frac{\partial L}{\partial W_1} = \frac{\partial L}{\partial Y_3}\frac{\partial Y_3}{\partial Y_2}\frac{\partial Y_2}{\partial Y_1}\frac{\partial Y_1}{\partial W_1} =(Y_3 - Y)^T \cdot \sigma'(W_3Y_2 + b_3)^T \times W_3 \cdot \sigma'(W_2Y_1 + b_2)^T \times W_2 \cdot \sigma'(W_1X+b_1)^T \times X ∂ W 1 ∂ L = ∂ Y 3 ∂ L ∂ Y 2 ∂ Y 3 ∂ Y 1 ∂ Y 2 ∂ W 1 ∂ Y 1 = ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × W 3 ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × W 2 ⋅ σ ′ ( W 1 X + b 1 ) T × X 我们会发现,在链式法则下,越上层的网络,梯度从底层传导回来经历的计算越多。如果层数变得更多的话,会导致很多问题:
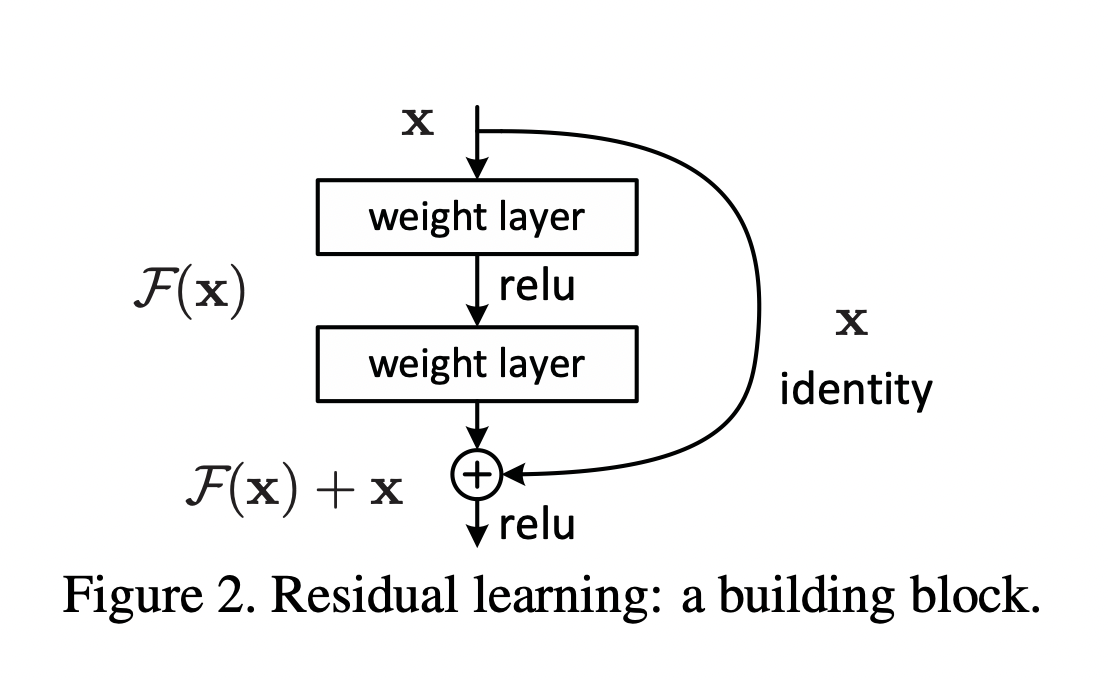
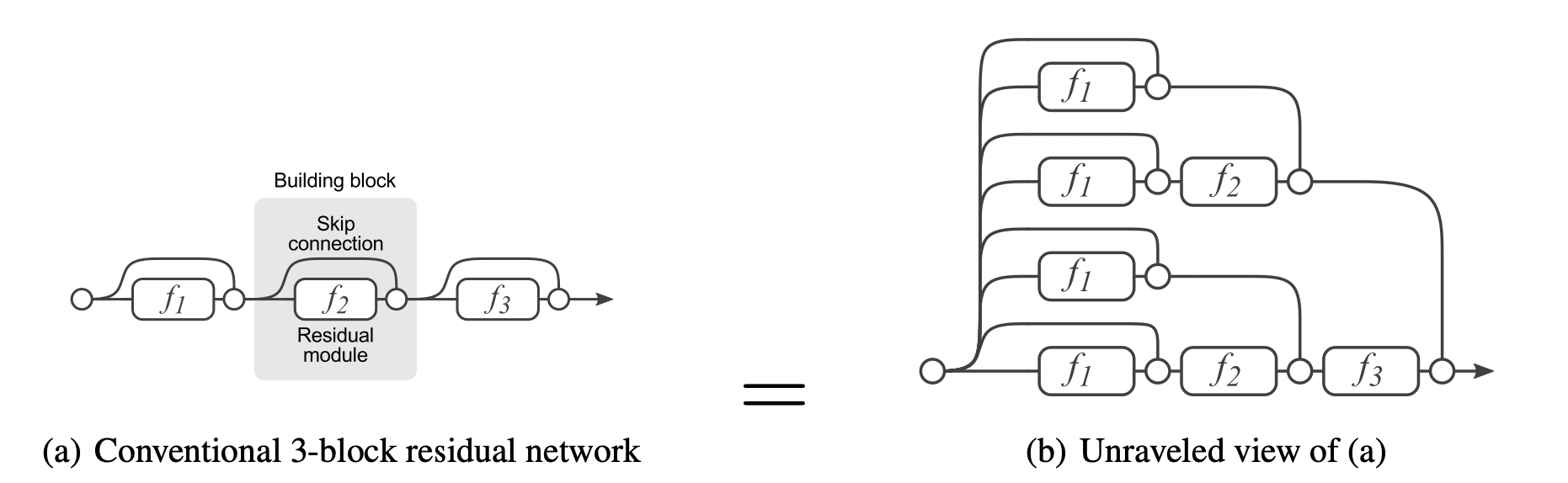
激活函数R e L U ReLU R e LU σ ′ ( x ) \sigma'(x) σ ′ ( x ) 0 0 0 0 0 0 由于我们一般采用随机梯度下降法训练(每次会从数据集中随机取一定数量样本训练),在计算梯度的过程中,必然会引入噪音(误差),这些噪音经过层层积累,将会越来越大,从而使得最上层得到的梯度面目全非(被噪音覆盖)。 上层网络的梯度运算中,涉及到下层网络参数W W W W W W sup ∥ f ( W x + b ) ∥ \sup \|f(Wx+b)\| sup ∥ f ( W x + b ) ∥ sup ∥ ∂ L / ∂ W ∥ \sup \|\partial L/\partial W\| sup ∥ ∂ L / ∂ W ∥ sup ∥ W ∥ \sup \|W\| sup ∥ W ∥ W W W 相信ResNet 的作者He Kaiming更能洞悉这些问题。再加上Highway Networks 的铺垫,ResNet的提出似乎是顺理成章的事情。ResNet的结构可谓是大道至简:
y = f ( x ; W ) + x y = f(x;W) + x \\ y = f ( x ; W ) + x 我们考虑有residual结构的三层MLP:
f W ( X ) = ( f 3 ∘ f 2 ∘ f 1 ) ( X ) Y 1 = f 1 ( X ) = σ ( W 1 X + b 1 ) Y 2 = f 2 ( Y 1 ) = σ ( W 2 Y 1 + b 2 ) + Y 1 Y 3 = f 3 ( Y 2 ) = σ ( W 3 Y 2 + b 3 ) + Y 2 L ( W ) = ∣ ∣ Y 3 − Y ∣ ∣ 2 2 f_W(X) = (f_3 \circ f_2 \circ f_1)(X)\\Y_1 = f_1(X)= \sigma(W_1X+ b_1)\\Y_2 = f_2(Y_1) = \sigma(W_2Y_1 + b_2) + Y_1\\Y_3 = f_3(Y_2) = \sigma(W_3Y_2 + b_3) + Y_2 \\L(W) = ||Y_3 - Y||_2^2 f W ( X ) = ( f 3 ∘ f 2 ∘ f 1 ) ( X ) Y 1 = f 1 ( X ) = σ ( W 1 X + b 1 ) Y 2 = f 2 ( Y 1 ) = σ ( W 2 Y 1 + b 2 ) + Y 1 Y 3 = f 3 ( Y 2 ) = σ ( W 3 Y 2 + b 3 ) + Y 2 L ( W ) = ∣∣ Y 3 − Y ∣ ∣ 2 2 那么
∂ L ∂ W 3 = ∂ L ∂ Y 3 ∂ Y 3 ∂ W 3 = ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × Y 2 ∂ L ∂ W 2 = ∂ L ∂ Y 3 ∂ Y 3 ∂ Y 2 ∂ Y 2 ∂ W 2 = ( Y 3 − Y ) T ⋅ ( σ ′ ( W 3 Y 2 + b 3 ) T × W 3 + 1 ) ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × Y 1 ∂ L ∂ W 1 = ∂ L ∂ Y 3 ∂ Y 3 ∂ Y 2 ∂ Y 2 ∂ Y 1 ∂ Y 1 ∂ W 1 = ( Y 3 − Y ) T ⋅ ( σ ′ ( W 3 Y 2 + b 3 ) T × W 3 + 1 ) ⋅ ( σ ′ ( W 2 Y 1 + b 2 ) T × W 2 + 1 ) ⋅ σ ′ ( W 1 X + b 1 ) T × X = ( Y 3 − Y ) T × 1 ⋅ σ ′ ( W 1 X + b 1 ) T × X + ( Y 3 − Y ) T × 1 ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × W 2 ⋅ σ ′ ( W 1 X + b 1 ) T × X + ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × W 3 × 1 ⋅ σ ′ ( W 1 X + b 1 ) T × X + ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × W 3 ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × W 2 ⋅ σ ′ ( W 1 X + b 1 ) T × X \begin{aligned}\frac{\partial L}{\partial W_3} =& \frac{\partial L}{\partial Y_3}\frac{\partial Y_3}{\partial W_3} =(Y_3 - Y)^T \cdot \sigma'(W_3Y_2 + b_3)^T \times Y_2 \\ \frac{\partial L}{\partial W_2} =& \frac{\partial L}{\partial Y_3}\frac{\partial Y_3}{\partial Y_2}\frac{\partial Y_2}{\partial W_2} =(Y_3 - Y)^T \cdot (\sigma'(W_3Y_2 + b_3)^T \times W_3 + \mathbf{1}) \cdot \sigma'(W_2Y_1 + b_2)^T \times Y_1 \\ \frac{\partial L}{\partial W_1} =& \frac{\partial L}{\partial Y_3}\frac{\partial Y_3}{\partial Y_2}\frac{\partial Y_2}{\partial Y_1}\frac{\partial Y_1}{\partial W_1} \\=& (Y_3 - Y)^T \cdot (\sigma'(W_3Y_2 + b_3)^T \times W_3 + \mathbf{1}) \cdot (\sigma'(W_2Y_1 + b_2)^T \times W_2 + \mathbf{1}) \cdot \sigma'(W_1X+b_1)^T \times X \\=& (Y_3 - Y)^T \times \mathbf{1} \cdot \sigma'(W_1X+b_1)^T \times X \\&+ (Y_3 - Y)^T \times \mathbf{1} \cdot \sigma'(W_2Y_1 + b_2)^T \times W_2 \cdot \sigma'(W_1X+b_1)^T \times X \\&+ (Y_3 - Y)^T \cdot \sigma'(W_3Y_2 + b_3)^T \times W_3 \times \mathbf{1} \cdot \sigma'(W_1X+b_1)^T \times X \\&+ (Y_3 - Y)^T \cdot \sigma'(W_3Y_2 + b_3)^T \times W_3 \cdot \sigma'(W_2Y_1 + b_2)^T \times W_2 \cdot \sigma'(W_1X+b_1)^T \times X\end{aligned} \\ ∂ W 3 ∂ L = ∂ W 2 ∂ L = ∂ W 1 ∂ L = = = ∂ Y 3 ∂ L ∂ W 3 ∂ Y 3 = ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × Y 2 ∂ Y 3 ∂ L ∂ Y 2 ∂ Y 3 ∂ W 2 ∂ Y 2 = ( Y 3 − Y ) T ⋅ ( σ ′ ( W 3 Y 2 + b 3 ) T × W 3 + 1 ) ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × Y 1 ∂ Y 3 ∂ L ∂ Y 2 ∂ Y 3 ∂ Y 1 ∂ Y 2 ∂ W 1 ∂ Y 1 ( Y 3 − Y ) T ⋅ ( σ ′ ( W 3 Y 2 + b 3 ) T × W 3 + 1 ) ⋅ ( σ ′ ( W 2 Y 1 + b 2 ) T × W 2 + 1 ) ⋅ σ ′ ( W 1 X + b 1 ) T × X ( Y 3 − Y ) T × 1 ⋅ σ ′ ( W 1 X + b 1 ) T × X + ( Y 3 − Y ) T × 1 ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × W 2 ⋅ σ ′ ( W 1 X + b 1 ) T × X + ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × W 3 × 1 ⋅ σ ′ ( W 1 X + b 1 ) T × X + ( Y 3 − Y ) T ⋅ σ ′ ( W 3 Y 2 + b 3 ) T × W 3 ⋅ σ ′ ( W 2 Y 1 + b 2 ) T × W 2 ⋅ σ ′ ( W 1 X + b 1 ) T × X 由上可以看出,在较上层的梯度(∂ L / ∂ W 1 \partial L/\partial W_1 ∂ L / ∂ W 1
避免因R e L U ReLU R e LU 避免梯度噪音的累积放大。 因为2减少的梯度噪音,梯度爆炸的概率也大大降低了。 在ResNet发布之后,有很多文章对其进行分析。其中有两篇值得一提:
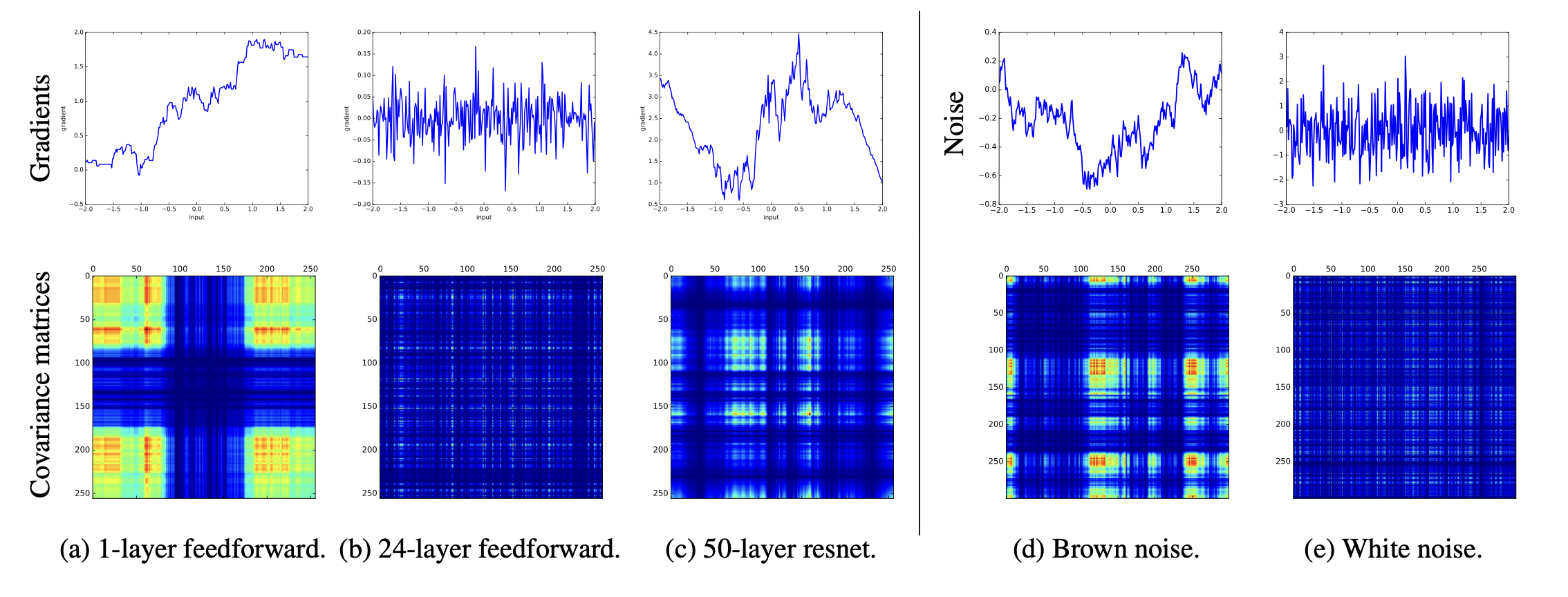
The Shattered Gradients Problem: If resnets are the answer, then what is the question? Residual Networks Behave Like Ensembles of Relatively Shallow Networks 第一篇详细的分析了梯度回传中的噪音问题,跟我们的分析非常一致。下图中(d) (e) 列的上行分别代表着采样自brown noise和white noise的数据;下行代表着数据点之间的covariance matrix。(a)(b)(c)的上行是取自单层MLP,24层MLP,和50层有residual结构的MLP的对输入数据(256个数据点取自[ − 2 , 2 ] [-2,2] [ − 2 , 2 ]
第二篇其实也很直观,一张图足以说明问题:
这也是正是其标题要表达的:
深度残差网络更像是其浅层子网络的集成。
ResNet有很多变种,有将residual block的addition操作改为channel concatenation的DenseNet ,有结合两者的DPN ,有将channel分组的ResNext ,有在channel上加attention的SENet ,甚至还有单纯增加网络宽度的WRN (我想说这也好意思单独发出来🐶),但是ResNet依然是最经典的。
如果说ResNet代表着大道至简的设计艺术,那么Inception系列更像是精雕细琢的艺术设计。Inception共有四个版本:V1 ,V2 ,V3 ,V4 ,设计原则都差不多,其中V2提出了Batch Normalization,影响了后来所有神经网络的设计。V4将residual结构加了进来。
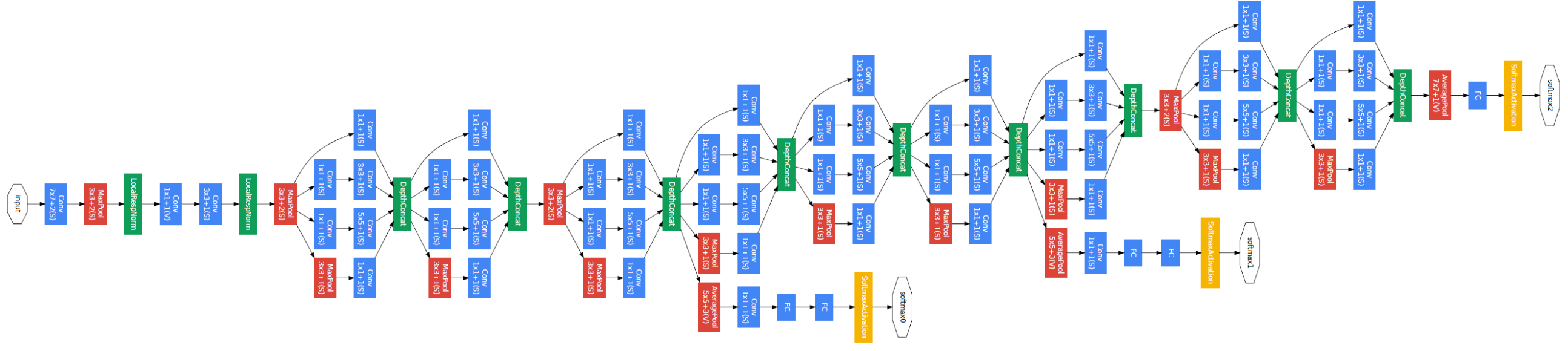
我们只看Inception V1,整个网络看起来是这个样子的:
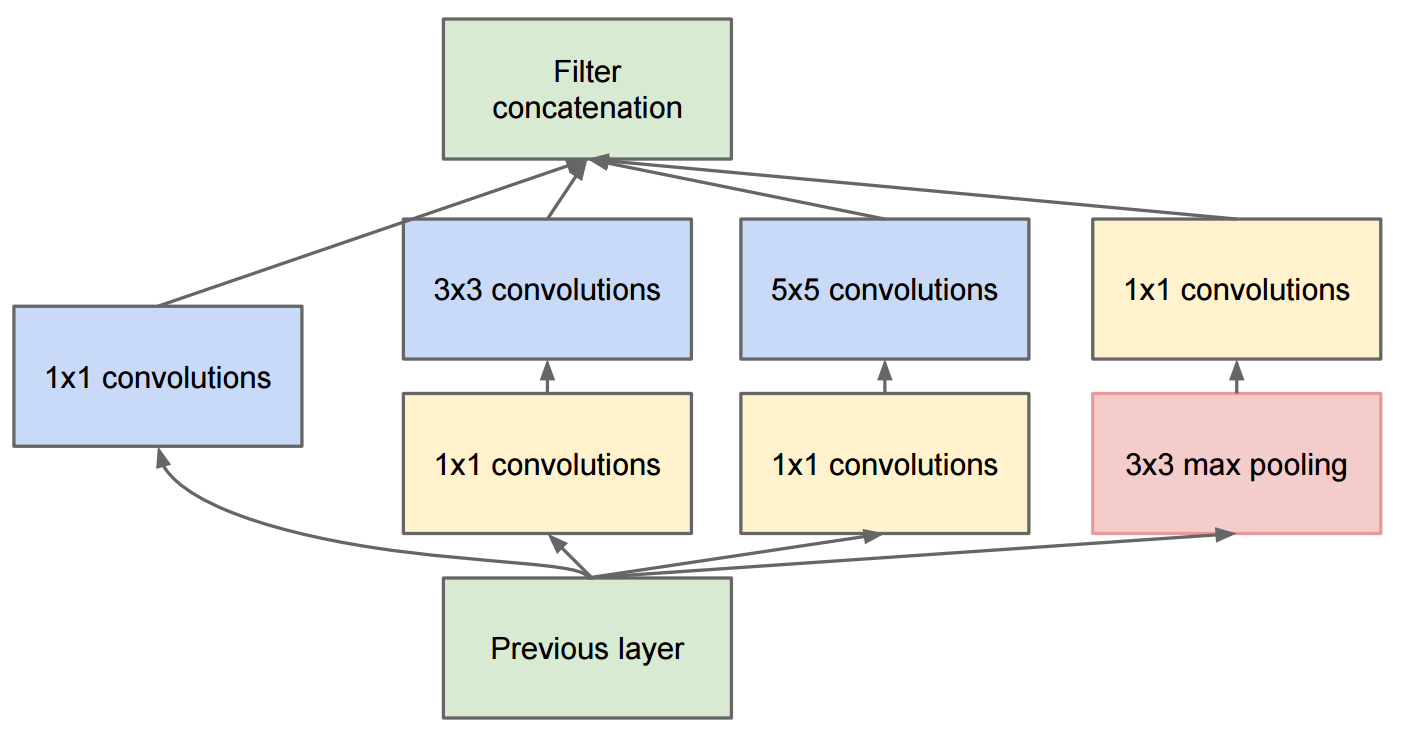
看起来很头疼,但实际上网络是由很多个相似的block叠加,而单个block看起来是下面这样。
我其实很不太理解是什么指导着Google设计出这样复杂的网络,但是大概琢磨着是这样的:
由于众所周知的卷积神经网络的Receptive Field的问题,虽然采用较大的卷积核能减少其负面影响,但带来的新问题是参数量和计算量的指数提升O ( n 2 ) O(n^2) O ( n 2 ) 好像效果还可以,顺着这个思路,我们再增加其他的操作,比如max pooling,比如将3 × 3 3\times3 3 × 3 3 × 1 3 \times 1 3 × 1 1 × 3 1 \times 3 1 × 3 3 × 1 + 1 × 3 = 6 < 3 × 3 = 9 3 \times 1 + 1 \times 3 = 6 < 3 \times 3 = 9 3 × 1 + 1 × 3 = 6 < 3 × 3 = 9 我们依此原则设计几十个这样的网络拿去训练(反正GPU多),选一个最好的发表出来。 Inception系列网络为google取得了非凡的成绩,也是人工设计网络的巅峰之作,同时,也为机器设计网络提供了灵感。
上节提到Inception中人工设计的成分,以 Google拥有的海量算力,让机器代替人去设计似乎是一件顺水推舟的事情。以当时该领域的火热程度,有这种想法的不会只有一个人。几乎在同一天,这个想法的两篇文章同时发表:
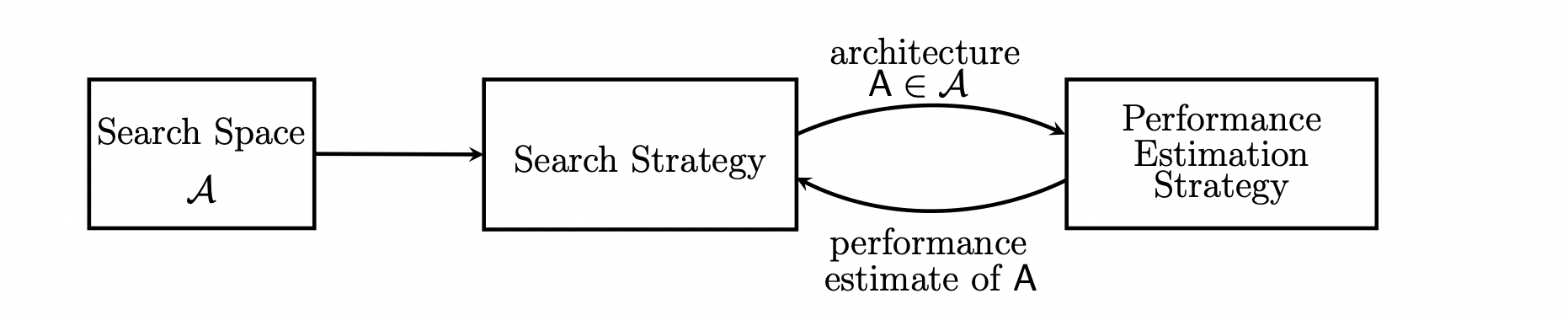
Designing Neural Network Architectures using Reinforcement Learning Neural Architecture Search with Reinforcement Learning 相较于Google的资源和影响力,1无论是从结果还是后续上都与2相差甚远,学术界的马太效应非常残酷。两者都试着用reinforcement learning来代替人工设计出更好的网络,设计思想用下图表示:
早期的设计是layerwise的,每一个layer给出几个候选的operation,从中sample。后期的设计是blockwise的,就是类似于Inception的block设计,这样就大大减少了搜索空间,提升了搜索效率。
Q Learning: metaQNN ,blockQNN Policy Gradient: NASNet Evolution: PNAS Gradient: DARTS Monte Carlo Tree Search Random Bayesian Optimization and others 对于1,2这两种搜索策略,我其实并不看好。一则是reinforcement learning本身学的很慢,消耗如此多的计算资源搜出来的网络,比消耗同样多计算资源随机采样出来的最好的网络,到底有多大提升,本应该打个问号。加上本领域常见的各种trick,使得这种文章的复现变得极为困难。另外,RL最怕的就是reward的随机性,在搜索后期,同一网络准确率的随机性,完全可以覆盖住RL算法想要带来的准确率提升,而RL本身又有很强的随机性。blockQNN用较短的周期训练出来的准确率,代替较长训练周期训练的准确率,则更是在这个问题上火上浇油(因为对于两个较好的网络,通常两者之间的相关性不高)。所以我怀疑,RL做NAS,与其说是在搜较好的网络,不如说在学习如何捕捉到较重的网络(较重和较好正相关,且更容易学到)。这这份怀疑,伴随着NAS101 的出现,得到了我的坐实。
至于4,我认为其马太效应会非常明显,因为不同layer之间的相关性得不到体现,相当于RL中没有exploration。这样显然背离了NAS的初衷(因为我们假设不同layer之间是有相关性的)。
至于6,本来应该拿来做baseline的,我在NAS101 的实验中发现,其实这个baseline已经很好了,124都很难超越(需要一点运气),而且即便超越,提升也非常有限。
反观3和5,我认为应该是最合适的搜索策略,但是却最得不到重视。原因是这两个方向没有RL火,学术界么,都喜欢凑热闹。
我们前面提到,由于搜索策略的低效性,我们通常采用blockwise search来减少搜索空间,然而此举显然会降低搜到的模型的上限。Randomly Wired Network 其实提供了另一种思路:在较好的大型搜索空间内,即便网络结构是随机生成的,也会有不错的表现。如果再往下走一步,其实就会更接近生物神经网络的生成模式了。
人的大脑的可塑性非常强。我们一出生,便拥有了一生所需的几乎所有的,且过量的神经元。大约15个月之后,神经元之间的突触连接数便达到最大。这之后,大脑变开始对这些错综复杂的神经连接进行剪枝,直到青春期结束,见这里 。而且即便在成年后,大脑也在不断的适应环境,不断的产生新连接和剪枝。
所以,我们能否设计出类似于人脑的学习算法,根据学到的数据,在不同的阶段,不断的更改网络结构呢?
另外,NAS其实属于AutoML的一个分支。训练一个模型,不仅要选择神经网络结构,而且还会需要选择太多的超参数(Hyperparameters, e.g. learning rate, optimizer, data augmentation),而这些参数的不同排列组合,即便对同一网络,也可能产生残差不齐的结果。不过这,就是另外一个话题了。
有关深度学习的理论,个人觉得平均场论 的解释非常平易近人。我们简单了解一下。
我们考虑一个hidden layer的MLP: y = ϕ ( W x + b ) y = \phi(Wx + b) y = ϕ ( W x + b ) W ∈ R N × N W \in \mathbb{R}^{N\times N} W ∈ R N × N b ∈ R N b \in \mathbb{R}^{N} b ∈ R N
w i j ∼ N ( 0 , σ w 2 / N ) , b ∼ N ( 0 , σ b 2 ) w_{ij} \sim \mathcal{N}(0, \sigma_w ^2/N), \quad b \sim \mathcal{N}(0, \sigma_b^2) w ij ∼ N ( 0 , σ w 2 / N ) , b ∼ N ( 0 , σ b 2 ) 我们设激活前数值h = W x + b h = Wx + b h = W x + b
q = 1 N ∑ j = 0 N ( h j ) 2 q = \frac{1}{N}\sum_{j=0}^N (h_j)^2 q = N 1 j = 0 ∑ N ( h j ) 2 我们知道,如果N ⋙ 1 N \ggg 1 N ⋙ 1 h j h_j h j
q t + 1 = σ w 2 E h [ ϕ 2 ( h t ) ] + σ b 2 h ∼ N ( 0 , q t ) q 0 = 1 N x T x q_{t+1} = \sigma_w^2\mathbb{E}_h[\phi^2(h_t)] + \sigma_b^2 \\h \sim \mathcal{N}(0, q_t) \\q_0 = \frac{1}{N}x^Tx q t + 1 = σ w 2 E h [ ϕ 2 ( h t )] + σ b 2 h ∼ N ( 0 , q t ) q 0 = N 1 x T x 如此不断迭代,我们期望得到一个不动点: q ∗ = lim t → ∞ q t q^* = \lim_{t \to \infty}q_t q ∗ = lim t → ∞ q t
如果输入信号是一对: x α , x β x_\alpha, x_\beta x α , x β
q t + 1 α , β = σ w 2 E h α , h β [ ϕ ( h α ) ϕ ( h β ) ] + σ b 2 h α , h β ∼ N ( 0 , Σ t ) Σ t = [ q t α q t α , β q t α , β q t β ] q 0 α , β = 1 N x α T x β q_{t+1}^{\alpha,\beta} = \sigma_w^2\mathbb{E}_{h_\alpha, h_\beta}[\phi(h_\alpha)\phi(h_\beta)] + \sigma_b^2 \\h_\alpha, h_\beta \sim \mathcal{N}(0, \Sigma_t) \\\Sigma_t = \begin{bmatrix}q_t^\alpha & q_t^{\alpha, \beta} \\q_t^{\alpha, \beta} & q_t^\beta\end{bmatrix} \\q_0^{\alpha, \beta} = \frac{1}{N}x_\alpha^T x_\beta q t + 1 α , β = σ w 2 E h α , h β [ ϕ ( h α ) ϕ ( h β )] + σ b 2 h α , h β ∼ N ( 0 , Σ t ) Σ t = [ q t α q t α , β q t α , β q t β ] q 0 α , β = N 1 x α T x β 且我们期望有不动点Σ ∗ = lim t → ∞ Σ t \Sigma^* = \lim_{t\to \infty} \Sigma_t Σ ∗ = lim t → ∞ Σ t
Σ ∗ = [ q α ∗ q α , β ∗ / q α ∗ q β ∗ q α , β ∗ / q α ∗ q β ∗ q β ∗ ] = [ q α ∗ q α , β ∗ / q ∗ q α , β ∗ / q ∗ q β ∗ ] \Sigma^* = \begin{bmatrix}q^*_\alpha & q^*_{\alpha, \beta} / \sqrt{q^*_\alpha q^*_\beta} \\q^*_{\alpha, \beta} / \sqrt{q^*_\alpha q^*_\beta} & q^*_\beta\end{bmatrix} = \begin{bmatrix}q^*_\alpha & q^*_{\alpha, \beta} / q^* \\q^*_{\alpha, \beta} / q^* & q^*_\beta\end{bmatrix} Σ ∗ = [ q α ∗ q α , β ∗ / q α ∗ q β ∗ q α , β ∗ / q α ∗ q β ∗ q β ∗ ] = [ q α ∗ q α , β ∗ / q ∗ q α , β ∗ / q ∗ q β ∗ ] 因为q α ∗ = q β ∗ = q ∗ q_\alpha^* = q_\beta^* = q^* q α ∗ = q β ∗ = q ∗ c ∗ = q α , β ∗ / q ∗ c^* = q_{\alpha, \beta}^* / q^* c ∗ = q α , β ∗ / q ∗
X c ∗ = lim t → ∞ ∂ c t + 1 ∂ c t = σ w 2 E h [ ϕ ′ ( h i ) ϕ ′ ( h j ) ] , i ≠ j X q ∗ = lim t → ∞ ∂ q t + 1 ∂ q t = σ w 2 E h [ ϕ ′ ′ ( h i ) ϕ ( h i ) + ϕ ′ ( h i ) ϕ ′ ( h i ) ] h ∼ N ( 0 , Σ ∗ ) \mathcal{X}_{c^*} = \lim_{t\to \infty} \frac{\partial c_{t+1}}{\partial c_t} = \sigma_w^2 \mathbb{E}_{h}[\phi'(h_i)\phi'(h_j)], \quad i \neq j \\ \mathcal{X}_{q^*} = \lim_{t\to \infty} \frac{\partial q_{t+1}}{\partial q_t} = \sigma_w^2 \mathbb{E}_{h}[\phi''(h_i)\phi(h_i)+\phi'(h_i)\phi'(h_i)] \\ h \sim \mathcal{N}(0, \Sigma^*) X c ∗ = t → ∞ lim ∂ c t ∂ c t + 1 = σ w 2 E h [ ϕ ′ ( h i ) ϕ ′ ( h j )] , i = j X q ∗ = t → ∞ lim ∂ q t ∂ q t + 1 = σ w 2 E h [ ϕ ′′ ( h i ) ϕ ( h i ) + ϕ ′ ( h i ) ϕ ′ ( h i )] h ∼ N ( 0 , Σ ∗ ) 对于不动点Σ ∗ \Sigma^* Σ ∗ X c ∗ < 1 , X q ∗ < 1 \mathcal{X}_{c^*}<1, \mathcal{X}_{q^*}<1 X c ∗ < 1 , X q ∗ < 1 q t q_t q t
∣ q t − q ∗ ∣ = k q e − t / ξ q ∗ , ξ q ∗ − 1 = − log X q ∗ ∣ c t − c ∗ ∣ = k c e − t / ξ c ∗ , ξ c ∗ − 1 = − log X c ∗ |q_t - q^*| = k_qe^{-t/\xi_{q^*}}, \quad \xi_{q^*}^{-1} = -\log \mathcal{X_{q^*}} \\|c_t - c^*| = k_ce^{-t/\xi_{c^*}}, \quad \xi_{c^*}^{-1} = -\log \mathcal{X_{c^*}} ∣ q t − q ∗ ∣ = k q e − t / ξ q ∗ , ξ q ∗ − 1 = − log X q ∗ ∣ c t − c ∗ ∣ = k c e − t / ξ c ∗ , ξ c ∗ − 1 = − log X c ∗ 如此,关于此动态系统的发散与否,只需要确定X c ∗ , X q ∗ \mathcal{X}{c^*}, \mathcal{X}{q^*} X c ∗ , X q ∗ ϕ , σ w , σ b \phi, \sigma_w, \sigma_b ϕ , σ w , σ b
对每个不动点的q ∗ q^* q ∗ X q ∗ = 1 \mathcal{X}_{q^*} = 1 X q ∗ = 1 σ w 2 = 1 / E [ ϕ ′ ( h i ) ϕ ′ ( h j ) ] , h i , h j ∼ Σ ∗ \sigma_w^2 = 1 / \mathbb{E}[\phi'(h_i)\phi'(h_j)], h_i, h_j \sim \Sigma^* σ w 2 = 1/ E [ ϕ ′ ( h i ) ϕ ′ ( h j )] , h i , h j ∼ Σ ∗ σ b 2 = q ∗ − σ w 2 \sigma_b^2 = q^* - \sigma_w^2 σ b 2 = q ∗ − σ w 2 q ∗ q^* q ∗ σ w 2 ∼ σ b 2 \sigma_w^2 \sim \sigma_b^2 σ w 2 ∼ σ b 2
我们取ϕ = tanh \phi = \tanh ϕ = tanh MF 的代码如下:
import numpy as np
from scipy. integrate import quad, dblquad
import warnings
import matplotlib. pyplot as plt
def f ( x) :
return np. tanh( x)
def df ( x) :
"""Derivative of tanh."""
return 1. / np. cosh( x) ** 2
def gauss_density ( x, mu, sigma) :
"""Density of Gaussian N(mu,sigma)."""
k = 1. / ( sigma * np. sqrt( 2 * np. pi) )
s = - 1.0 / ( 2 * sigma * sigma)
return k * np. exp( s * ( x - mu) * ( x - mu) )
def qmap_density ( h, q) :
"""Compute the density function of the q-map."""
return gauss_density( h, 0. , np. sqrt( q) ) * ( f( h) ** 2 )
def chi_c1_density ( h, q) :
"""Compute the density function of chi_c=1."""
return gauss_density( h, 0. , np. sqrt( q) ) * ( df( h) ** 2 )
def sw_sb ( q, chi1) :
"""
Compute the critical line. Set chi1=1, return variances of weight and
bias on the critical line with qstar=q.
"""
with warnings. catch_warnings( ) :
warnings. simplefilter( "ignore" )
sw = chi1 / quad( chi_c1_density, - np. inf, np. inf, args= ( q) ) [ 0 ]
sb = q - sw * quad( qmap_density, - np. inf, np. inf,
args= ( q) ) [ 0 ]
return sw, sb
def simple_plot ( x, y) :
plt. plot( x, y)
plt. xlim( 0.5 , 3 )
plt. ylim( 0 , 0.25 )
plt. xlabel( '$\sigma_\omega^2$' , fontsize= 16 )
plt. ylabel( '$\sigma_b^2$' , fontsize= 16 )
plt. show( )
def main ( ) :
qrange = np. linspace( 1e-5 , 2.25 , 50 )
sw_sbs = [ sw_sb( q, 1.0 ) for q in qrange]
sw = [ sw_sb[ 0 ] for sw_sb in sw_sbs]
sb = [ sw_sb[ 1 ] for sw_sb in sw_sbs]
simple_plot( sw, sb)
main( )
同理,我们固定σ b 2 = 0.05 \sigma_b^2=0.05 σ b 2 = 0.05 σ w 2 \sigma_w^2 σ w 2 X q ∗ \mathcal{X}_{q^*} X q ∗ q ∗ q^* q ∗ σ w 2 ∼ t ∼ ∣ q t − q ∗ ∣ \sigma_w^2 \sim t \sim |q_t - q^*| σ w 2 ∼ t ∼ ∣ q t − q ∗ ∣ σ w 2 = 1.75 \sigma_w^2 = 1.75 σ w 2 = 1.75 X q ∗ = 1 , ξ q ∗ − 1 = 0 \mathcal{X}_{q^*} = 1, \xi_{q^*}^{-1}=0 X q ∗ = 1 , ξ q ∗ − 1 = 0 ∣ q t − q ∣ = k q |q_t - q| = k_q ∣ q t − q ∣ = k q
总之,平均场论主要回答了一下问题:神经网络参数的初始化,是如何影响模型的收敛性的?其理论推论与实验高度吻合,可以说是深度学习理论里,少有的干得漂亮的作品。