- Published on
Introduction to AgentZero: A Distributed Fast Reinforcement Learning Framework
- Authors

- Name
- ZHOU Bin
- @bzhouxyz
Preface
I started AgentZero project about two years ago. Before that, there were several reinforcement learning frameworks written in Tensorflow, e.g. OpenAI Baselines, Dopamine. As we all know, Tensorflow program is hard to read, modify and write; and is subsequently replaced by Pytorch in both research and industry usage.
At that time, it was difficult to find RL frameworks that have good readibility, fast training speed, excellent logging system, decent benchmarks and written in PyTorch. Still, there were several interesting projects inspiring me to start this project:
- DeepRL: Most of design ideas of this project come from this repo, which give a big boost to training speed of DeepRL Agents.
- Ray: It is the best distributed learning framework I ever used by that time. Although it has an RL library, but is written in Tensorflow and has poor readability.
- ChainerRL: it was later integrated to pfrl. It is from a Japanese Startup called Preferred Networks. PFRL provides a solid reproduction result.
Even before I start this project, I have written a non-systemmetic RL project called pt-baselines which covers major RL algorithms.
About AgentZero
AgentZero is a Ray & PyTorch based light-weight Distributed Fast Reinforcement Learning Framework.
It covers all RL algorithms mentioned in Deep RL Post and Distributional RL Post:
- DQN
- Double DQN
- Dueling DQN
- Prioritized Experience Replay
- Noisy Network
- C51
- Rainbow
- QR-DQN
- IQR
- FQF
- DDPG
- SAC
- TD3
- MDQN
And will continuing adding more algorithms.
AgentZero has the following great features:
- An Actor-Learner agent framework, which allows multiple actors to sample transitions asynchronously, boosting training speed by a great leap
- A fast asynchronous RAM Efficient experience replay, which stores image frames in compressed format, and collects transitions from actors, sampling data and passing to trainer asynchronously (with independent thread)
- Integrated hyperparameters in
config.pywhich allows parsing as arguments by command line. - Allowing grid search on hyperparameters for tuning by Ray
- A decent logging system for command line and CSV progress report, thanks to Ray
Related Works
Original DQN takes several days to complete training.
The idea that using multiple actors were first introduced in A3C, with more computation resources, the training speed could be flying high. The idea was later adopted by many papers. IMPALA uses a ditributed Actor-Learner architecture, boosting the performance to next level; however without replay memory, the algorithm is very data inefficient. APE-X DQN use a distributed replay memory to solve the problem. [APE-X DQN] summarize the different algorithms in the following table:
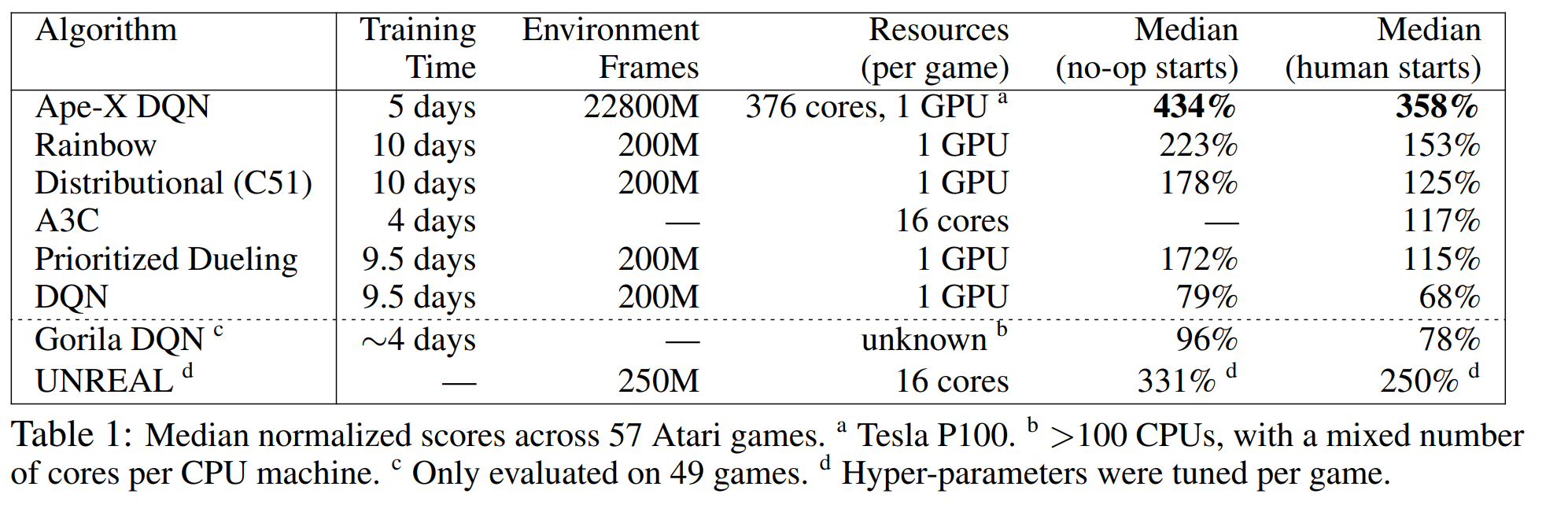
Our framework is very similar to APE-X, but with many optimizations, making it faster, extensive and adjustable to different computation resources. To our surprise:
AgentZero achieved around 3000 FPS on a AMD EPYC 7251 8-Core Processor @2.1GHz with a single RTX 2080Ti GPU, which means it can finish the training @10M frames within 1 hrs on rainbow algorithm setting.
Since it is adjustable, given more computation resources, the training speed of our framework will definitely match and surpass the above algorithms.
Design Keypoint
A typical DQN algorithm running as below:
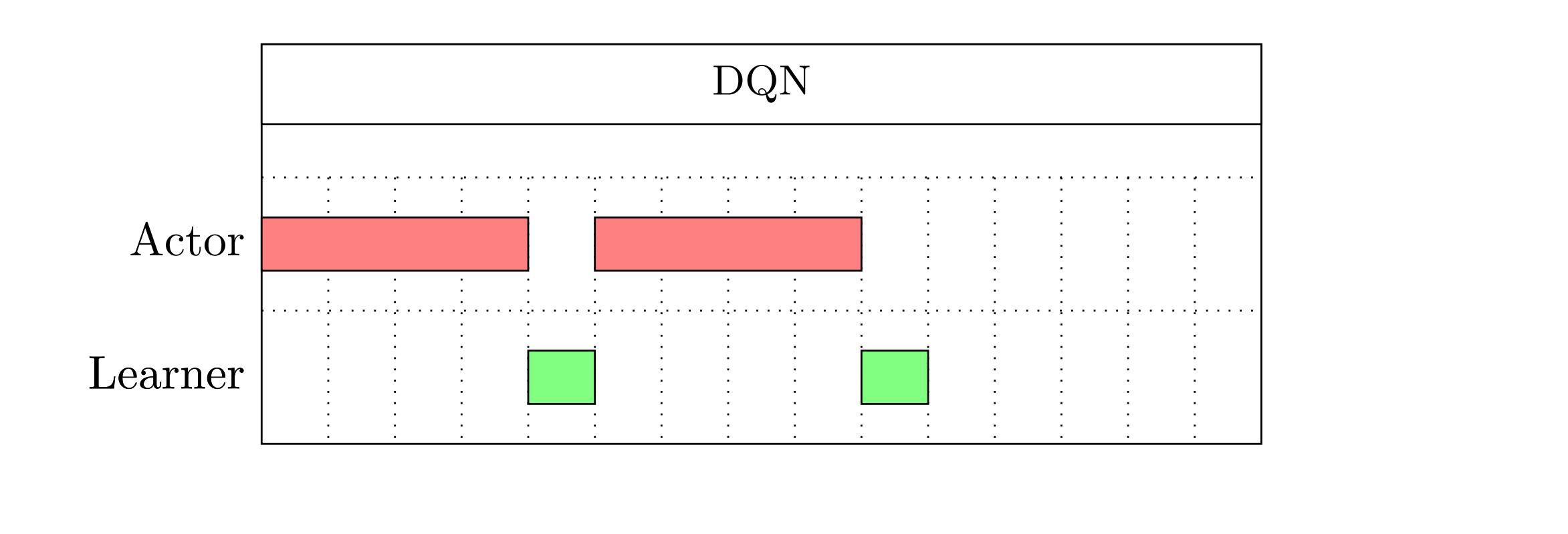
Notice the length of bar only represents number of steps by actor and learner, and DOES NOT reflect the duration of steps.
An actor samples several transitions, push them into replay memory, then the leaner draw transitions from replay memory, and update weights with data.
With multiple actors, the agent could sample data in multiple times faster than original one:

The speed could be further improved with asynchronous actors:
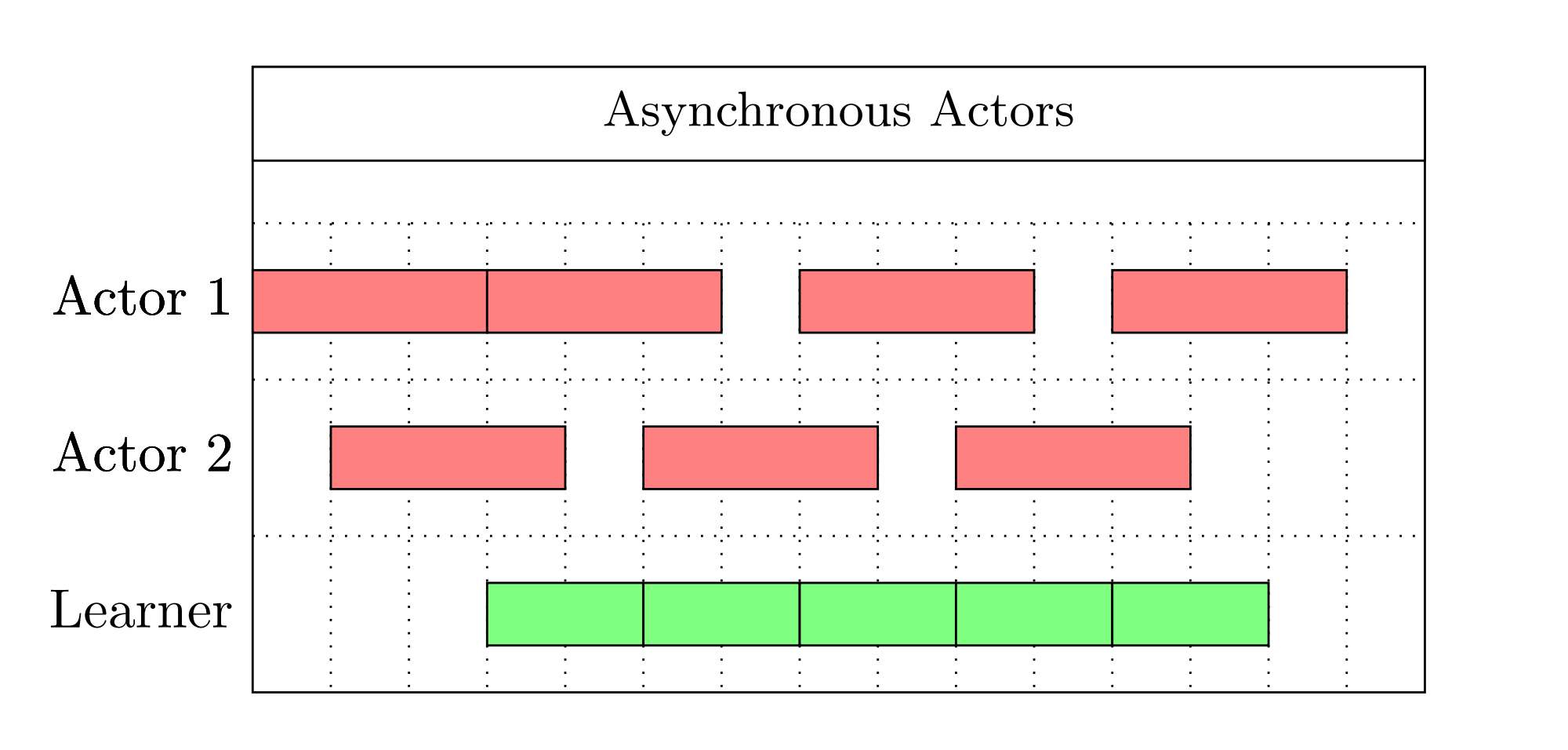
Since the learner GPU is fully utilized in this scenario, adding more actors will not increase the training speed of the agent. In pratical, only two actors will be enough. The bottlenet is the learner's speed; from my profiling, the data transfer from CPU to GPU takes longest waiting time.
Shared Memory Vector Environment and Multiple Actors
The shared Memory Vector Environment, which was first used by OpenAI Baselines, allows multiple environments running synchronous on a single actor. With multiple actors, I tested their sampling speed on a workstation with a Intel Xeon Gold 6132 CPU and a NVIDIA GTX 2080Ti GPU on number of environments against number of GPU/CPU actors and got the following result.
| envs \ GPU actors | 1 | 2 | 4 | 8 | 16 | 32 |
|---|---|---|---|---|---|---|
| 2 | 530 | |||||
| 4 | 854 | 7900 | ||||
| 8 | 1017 | 25000 | ||||
| 16 | 1292 | 10000 | 14000 | 26000 | ||
| 32 | 1736 | 7800 | 7800 | 12000 | 16000 | 27000 |
| envs \ CPU actors | 4 | 8 | 16 | 32 |
|---|---|---|---|---|
| 4 | 1800 | 3200 | 5588 | 7322 |
| 8 | 2395 | 4385 | 6900 | 7800 |
| 16 | 3028 | 5867 | 7900 | 6338 |
| 32 | 4078 | 6600 | 6750 | 5539 |
Since we only have 2 GPU actors, we choose 16 environments per actor to balance the speed and computation resources. Our architecture is similar to that of APE-X which I put below, except we have multiple environments per actor; in addition, all the operations between learner, replay and actors are asynchronous.
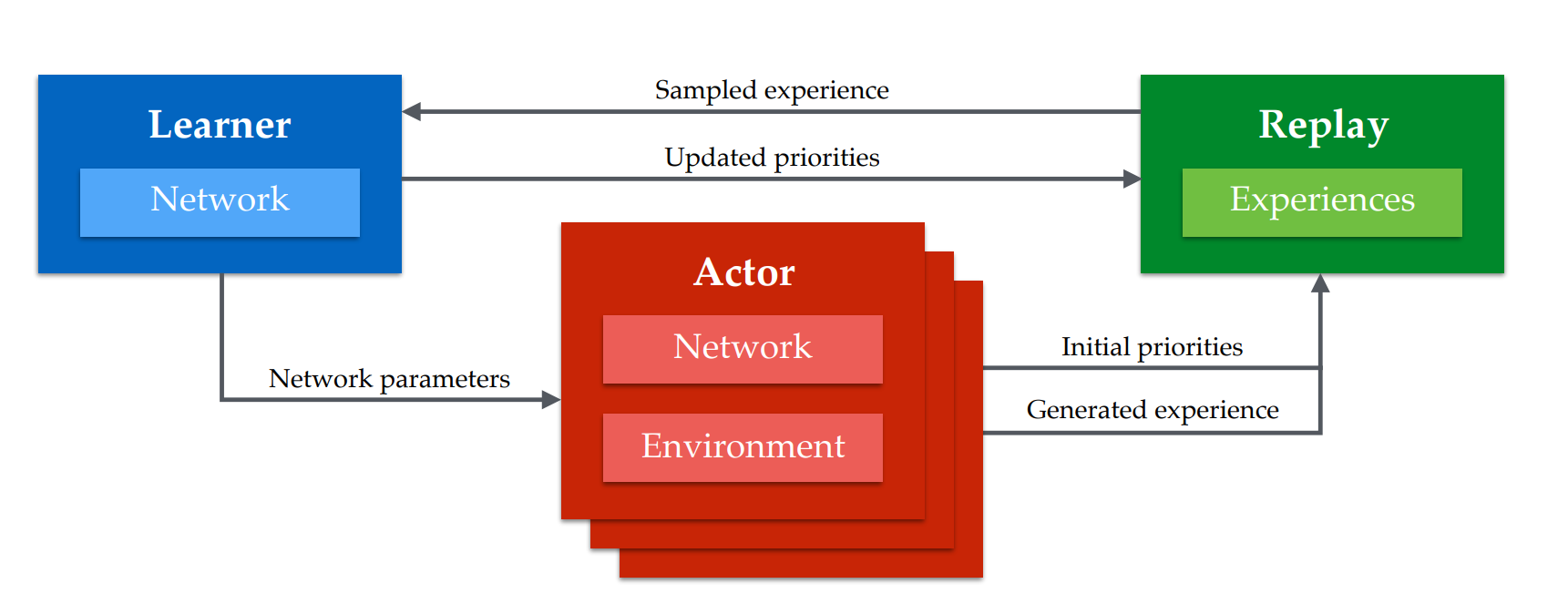
Compressed Frames
We use LZ4 lossless compression algorithm for python to compress the stacked frames, which reduced the replay experience RAM usage to around 20% of the original, allowing more trials running on single workstation.
NVIDIA has made a GPU version of this algorithm, called nvcomp, however lacks a python interface. If made possible, the whole replay experience could be placed onto GPU memory, which will make DRL even faster, as I proposed at this issue.