这篇提出一种Conservative Policy Iteration algorithm,可以在较小步数内,找到近似最优策略(Approximately Optimal Policy),这也是知名的Trust Region Policy Optimisation的前作。
文章第二部分给出一些RL的基本定义:
Vπ(s)=(1−γ)Es,a[t=0∑∞γtR(st,at)∣π,s]Qπ(s,a)=(1−γ)R(s,a)+γEs′[Vπ(s′)∣π,s] 这里加1−γ是为了让Vπ(s),Qπ(s,a)∈[0,Rmax],因为
Es,a[t=0∑∞γtR(s,a)∣π]≤Rmax+γRmax+⋯=Rmax/(1−γ) 这样advantage function
Aπ(s,a)=Qπ(s,a)−Vπ(s,a)∈[−Rmax,Rmax] 还给出了一个 discounted future state distribution 的定义
dπ,D=(1−γ)t=0∑∞γtPr(st=t∣π,D) 这样,给定一个 start state distribution D, policy optimization 的目标函数
ηD(π)=Es∼D[Vπ(s)]=Es,a∼dπ,π[R(s,a)] 我们展开的话,会发现:
τ=(s0,a0,s1,a1,…),s0∼D,at∼π(st),st+1∼Pr(s′∣s=st,a=at)Pr(τ)=D(s0)t=0∏∞π(st,at)Pr(st+1∣st,at)R(τ)=(1−γ)t=0∑∞γtR(st,at)η(π)=Eτ[R(τ)] 由上很容易推出:
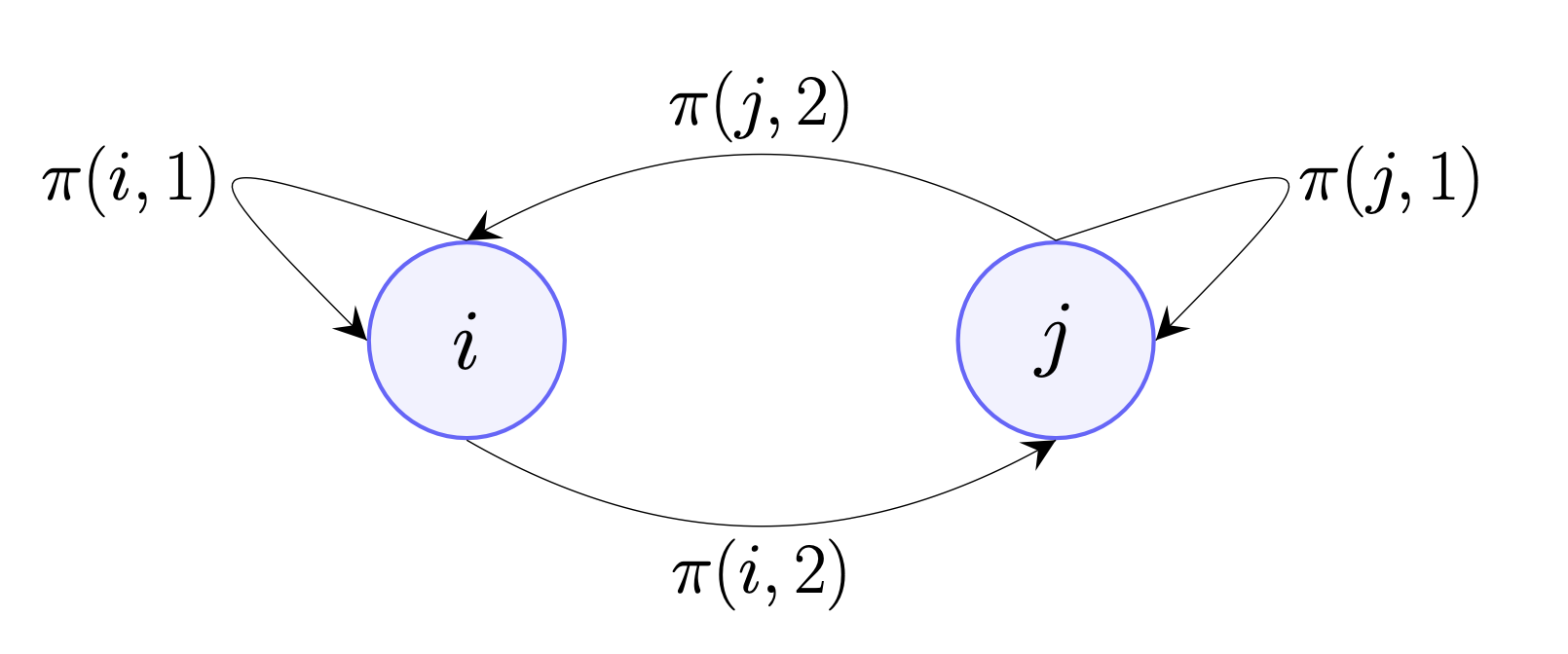
η(π)=s∑dπ,D(s)a∑π(s,a)Q(s,a) 文章第三部分,主要提出policy optimization 面临的两大难题,Figure 3.1 是sparse reward的问题;Figure 3.2是flat plateau gradient的问题。我们讨论Figure 3.2的case。
该图所示MDP有 i,j 两个states, initial state distribution 为 p,initial policy为π,具体如下
p(i)=0.8,p(j)=0.2π(i,1)=0.8,π(i,2)=0.2π(j,1)=0.9,π(j,2)=0.1R(i,1)=1,R(j,1)=2,R(i,2)=R(j,2)=0 很显然, state j 的self loop为最优解。
我们考虑一个parameterized policy function
πθ(s,a),π(a∣s)=∑eθseθs,θ∈R∣S∣×∣A∣ 对应到此MDP,θ 是2×2 的矩阵,对目标函数求导:
∇θη(π)=s,a∑d(s)∇π(s,a)Qπ(s,a) 我们这里肯定是希望增加 θi,2,θj,1,然而:
∇θi,2η=d(i)Q(i,2)π(i,2)(1−π(i,2))−d(i)Q(i,1)π(i,1)π(i,2)∇θj,1η=d(j)Q(j,1)π(j,1)(1−π(j,1))−d(j)Q(j,2)π(j,1)π(j,2) 第一项,Q(i,1)≫Q(i,2) ,第二项,因为d(j)≪d(i),
这样,policy gradient 非常小,学的就太慢了。本文就是为了解决这种问题而生。
文章考虑以下混合策略:
πnew=(1−α)π+απ′,α∈[0,1]π′=π+∇π 我们记policy advantage:
Aπ(π′)=s∑d(s,π)a∑π′(s,a)A(s,a) 给出引理一如下:
Lemma 1.
η(πnew)−η(π)≥αAπ(π′)−1−γ(1−α)2α2γϵϵ=1−γ1smaxa∑π′(s,a)Aπ(s,a)
证明以上引理,首先,
∇αη(πnew)=s∑d(s,πnew)a∑((1−α)π+απ′)Qπnew=s∑d(s,πnew)a∑(π′−π)(Vπnew+Aπnew) 那么当α→0,πnew→π,
∇ηα(πnew)∣α=0=s∑d(s,π)a∑(Vπ+Aπ)(π′−π)=s∑d(s,π)Vπa∑(π′−π)+s∑d(s,π)a∑Aπ(π′−π)=s∑d(s,π)a∑Aπ(π′−π)=s∑d(s,π)a∑Aππ′=Aπ(π′) 以上倒数第二,三是因为:
a∑(π−π′)=a∑π−a∑π′=1−1=0s∑d(s,π)a∑Aππ=s∑d(s,π)a∑(Qπ−Vπ)π=s∑d(s,π)a∑πQπ−s∑d(s,π)Vπa∑π=η(π)−η(π)=0 根据泰勒展开:
η(πnew)=η(π)+α∇αη(πnew)+O(α2) 那么
η(πnew)−η(π)=αAπ(π′)+O(α2) 先hold一下,我们给出引理二:
Lemma 2.
η(π^)−η(π)=s∑d(s,π^)a∑π^(s,a)Aπ(s,a)
证明:
η(π^∣s1)=Vπ^(s1)=Es,a∼π^[t=1∑∞γt−1R(st,at)∣s1]=t=1∑∞γt−1Es,a∼π^[R(st,at)+Vπ(st)−Vπ(st)∣s1]=t=1∑∞γt−1Es,a∼π^[R(st,at)+γVπ(st+1)−Vπ(st)∣s1]+Vπ(s1)=t=1∑∞γt−1Es,a∼π^[Qπ(st,at)−Vπ(st)∣s1]+Vπ(s1)=s∑d(s,s1,π^)a∑π^(s,a)Aπ(s,a)+Vπ(s1) 倒数第三步是因为:
==t=1∑∞γt−1Es,a∼π^[γVπ(st+1)∣s1]+Vπ(s1)Es,a∼π^[Vπ(s1)+γVπ(s2)+γ2Vπ(s3)+…∣s1]t=1∑∞γt−1Es,a∼π^[Vπ(st)∣s1] 因为initial state distribution 相等,所以
η(π^)=s∑d(s,π^)a∑π^(s,a)Aπ(s,a)+η(π)η(π^)−η(π)=s∑d(s,π^)a∑π^(s,a)Aπ(s,a) 引理二证毕。我们回过头继续证明引理一,对比下发现:
η(πnew)−η(π)η(πnew)−η(π)=αAπ(π′)+O(α2)=s∑d(s,πnew)a∑πnew(s,a)Aπ(s,a) 据此提示,我们来求余项:
η(πnew)−η(π)=s∑d(s,πnew)a∑πnew(s,a)Aπ(s,a)=Es∼πnew[t∑γt−1a∑πnewAπ]=Es∼πnew[t∑γt−1a∑απ′Aπ] 这里还是用了∑aπAπ=0 的性质。接下来我们这么想, πnew∼(π(s,a),π′(s,a)) with probability (1−α,α),那么,在前t步一直取 πnew=π 的概率为1−pt=(1−α)t,那么pt=1−(1−α)t,我们记前t步取π(s,a)的次数为nt, 那么nt=0 意味着在前t 步πnew=π,所以
=====≥===≥η(πnew)−η(π)Es∼πnew[t∑γt−1a∑απ′Aπ]αt∑(1−pt)γt−1Es∼πnew[a∑π′Aπ∣nt=0]+αt∑ptγt−1Es∼πnew[a∑π′Aπ∣nt>0]αt∑(1−pt)γt−1Es∼π[a∑π′Aπ∣nt=0]+αt∑ptγt−1Es∼πnew[a∑π′Aπ∣nt>0]αt∑γt−1Es∼π[a∑π′Aπ]−αt∑ptγt−1Es∼π[a∑π′Aπ∣nt=0]+αt∑ptγt−1Es∼πnew[a∑π′Aπ∣nt>0]αAπ(π′)−αt∑ptγt−1Es∼π[a∑π′Aπ∣nt=0]+αt∑ptγt−1Es∼πnew[a∑π′Aπ∣nt>0]αAπ(π′)−2αt∑pt−1γt−1smaxa∑π′AπαAπ(π′)−2αϵ(1−γ)t∑(1−(1−α)t−1)γt−1αAπ(π′)−2αϵ(1−γ)(1−γ1−1−(1−α)γ1)αAπ(π′)−2αϵ1−(1−α)γαγαAπ(π′)−1−γ2α2ϵ 这里maxs∑aπ′Aπ=ϵ(1−γ),那么
η(πnew)−η(π)≥αAπ(π′)−2αϵ1−(1−α)γαγ 至此,引理一证毕。
回过头看,引理一说明了什么?它说明,如果我们用这种混合策略,那么我们就能保证了策略效果提升的下界。有了以上引理,我们接下来确定混合策略的参数α 。
我么知道
ϵ=1−γmaxs∑aπ′Aπ≤R/(1−γ) 那么
αAπ(π′)−1−γ2α2ϵ≥0⇒α≤(1−γ)2Aπ(π′)/2R 我们取
α=(1−γ)2Aπ(π′)/4R 即可确保
η(πnew)−η(π)≥8RAπ(π′)2(1−γ)2 好了,有了以上理论基础,我们来看看作者提出的算法。假设我们有一个advantage function approximator
A^π(s,a)≈Aπ(s,a) 我们设
A^=s∑d(s,π)amaxA^(s,a) 即可确保
(1−γ)A^≥(1−γ)π′maxAπ(π′)−δ/3 如何确保?我们用NN来做advantage function approximator
fw(s,a)=A^π (1−γ)s∑dπ(s)amax∣Aπ(s,a)−fw(s,a)∣ 以上loss可通过 π 的采样获得,需要至少轨迹数为
ϵ2R2logϵ2R2 如果 (1−γ)A^≤2δ/3 则停止更新策略,否则:
π←(1−α)π+απ′π′=argamaxfw(s,a)α=(A^−3(1−γ)δ)4R(1−γ)2 那么以上算法,可确保(1−γ)A^≥2δ/3,从而
Aπ(π′)=A^−3(1−γ)δ≥3(1−γ)δ 因此
η(πnew)−η(π)≥8RAπ(π′)2(1−γ)2≥9(1−γ)2δ28R(1−γ)2=72Rδ2 因为对于任意π:η(π)≤R/(1−γ),所以我们最多需要
1−γRδ272R 使得
amax′Aπ(π′)≤δ 总结算法如下:
- 初始化 fw(s,a) ,随机策略π ,确定 δ,γ
- 求出 A^=maxafw(s,a) ,用 π 采样,计算Aπ(s,a) ,更新fw
- 如果(1−γ)A^≤2δ/3 ,结束算法,返回策略π
- 否则π′=argmaxafw(s,a);π←(1−α)π+απ′,回到第二步
以上就是Approximately Optimal Approximate RL的内容。